Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Antecedentes: La Prehistoria de la agregación Datos Arqueologicos
En 2013, no había más de seis repositorios digitales que ofrecieran instalaciones para la preservación a largo plazo y el acceso a datos arqueológicos a nivel nacional (Richards, 2017, 233). En la última década, esta situación ha mejorado, aunque todavía es irregular. Una encuesta de 2021, realizada bajo los auspicios de ARIADNEplus y la Acción COST SEADDA, se recopiló información sobre 60 repositorios, de los cuales 43 estaban operativos y 17 se estaban configurando (Geser et al., 2022). No obstante, todavía hay solo una pequeña cantidad de repositorios de datos arqueológicos que tienen la acreditación CoreTrustSeal (ADS, DANS, SND, tDAR y ARCHE). La encuesta sobre el estado del arte realizada por SEADDA y el Consejo Arqueológico Europeo revelaron un panorama muy variado con falta de mandatos de depósito exigibles, así como de instalaciones para su almacenamiento digital en la mayoría de los países (Richards et al., 2021). Sin embargo, sigue siendo claro que, en el ámbito del patrimonio, las infraestructuras nacionales son el nivel adecuado para la curación de datos. Esto es menos directo en las ciencias físicas y químicas, donde los datos se recopilan a través de infraestructuras digitales internacionales compartidas (como el CERN) o donde los datos se relacionan con fenómenos que trascienden el planeta Tierra (como en astrofísica), entonces los repositorios nacionales tienen poco sentido.
En el sector del patrimonio, sin embargo, los datos generalmente se recopilan dentro de marcos legales y pautas nacionales, y se relacionan con características que tienen coordenadas geoespaciales fijas que existen dentro de las fronteras políticas. Existen excepciones en algunos países federales, como Alemania, donde la protección del patrimonio opera a nivel estatal (por ejemplo, Bibby, 2021), y en los Estados Unidos (Nicholson, Fernández e Irwin, 2021), aunque en este último, los principales patrocinadores del trabajo que crean información en arqueología tienden a ser agencias federales nacionales. Pero en general, la arqueología se organiza a nivel estatal nacional, y las agencias nacionales de patrimonio toman la delantera en estipular normas para el registro de los datos y dirección de marcos y prioridades de investigación, incluso si son aplicadas por organismos regionales. En el sector universitario y de investigación, la mayoría de los financiamientos están sujetos a reglas nacionales sobre depósito de datos y acceso abierto, aunque estos pueden reflejar tendencias internacionales. Además, vale la pena señalar que la sostenibilidad de los repositorios digitales capaces de manejar la amplia variedad de tipos y formatos de datos arqueológicos requiere una masa crítica de financiamiento, personal y experiencia que en muchos países no es factible a nivel regional. Los repositorios también necesitan respaldo organizativo y compromiso a largo plazo, y si sus recursos también van a ser “confiables” en el sentido más convencional, entonces es esencial es esencial alguna huella institucional acreditada.
Ciertamente, existe el riesgo de que una red de repositorios que operan a nivel nacional cree una serie de “silos” de datos. De hecho, los repositorios digitales deben hacer dos cosas: deben reunir recursos y facilitar a los usuarios su interrogación a través de interfaces compartidas y fáciles de usar; pero también deben abrir los datos: mediante API, protocolos de cosecha como OAI-PMH y como Linked Open Data (LOD) para que puedan ser vistos y manipulados a través de múltiples rutas (May et al., 2015). También es importante reconocer las preocupaciones planteadas por Huggett (2015) de que al agregar datos sacamos los datos fuera del contexto en el que se recopilaron en primer lugar, y en ausencia de paradatos que describan ese contexto, corremos el riesgo de un mal uso. A medida que agregamos datos a un nivel cada vez más alto, los riesgos aumentan, ya que podemos separar los datos de los valores culturales y sociales en los que se registraron. Los estándares de metadatos que empleamos generalmente fueron producidos por arqueólogos educados en una tradición positivista occidental, y debemos prestar atención tanto a los principios de datos FAIR como a los de CARE para evitar imponer inadvertidamente perspectivas postcoloniales. En este sentido, el trabajo del proyecto TETRARCHs en explorar otros tipos de metadatos para fomentar diferentes formas de reutilización de datos es importante. Sin embargo, las preguntas de investigación arqueológica rara vez coinciden con las fronteras políticas modernas, que fueron irrelevantes durante la gran mayoría del lapso de tiempo del pasado humano. Grandes preguntas de investigación requieren grandes datos, y es nuestro papel catalogarlos con sensibilidad y teniendo en cuenta todos los matices de la observación humana y las diferentes perspectivas.
Tan temprano como en 1992, Henrik Jarl Hansen expresó la necesidad de unir recursos digitales en toda Europa (Figura 1) (Hansen, 1992), y la Comisión Europea ha sido una agencia de financiamiento clave que ha facilitado varios proyectos en esta área. El primero fue AQUARELLE (1996-99), que diseñó una arquitectura de descubrimiento de recursos que permite la difusión de consultas a fuentes de datos distribuidas y heterogéneas de museos y el dominio del patrimonio (Michard et al.,1998). El proyecto colaboró con el consorcio CIMI de museos y bibliotecas estadounidenses para utilizar un perfil de aplicación Z39.50 para habilitar la difusión de consultas y un sistema de software para crear y gestionar recursos terminológicos multilingües.
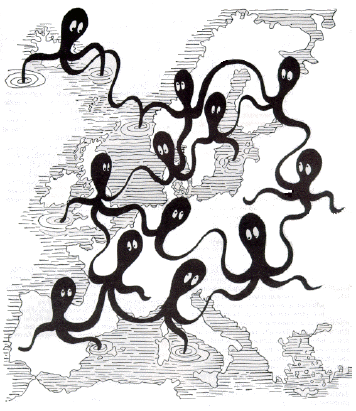
Figure 1: Hansen’s octopi symbolising the networking of European resources (reproduced from Hansen, 1992).
Entre 2002 y 2004, el Servicio de Datos de Arqueología (ADS) lideró un consorcio de socios europeos en el proyecto ARENA, financiado en el marco del programa Cultura 2000 (Kenny y Richards, 2005). Uno de los resultados del proyecto fue un portal que proporcionaba, a través de una búsqueda cruzada, registros de sitios y monumentos para seis países: Dinamarca, Islandia, Noruega, Polonia, Rumania y el Reino Unido (Figura 2) (Dam y Hansen, 2005). El portal ARENA se completó en 2004 y se lanzó en la conferencia de la Asociación Europea de Arqueólogos en Lyon.

Figure 2: The landing page of the ARENA search portal, developed during the ARENA project 2002-2004, provided a distributed cross-search of catalogues of sites and monuments data for Denmark, Iceland, Norway, Poland. Romania and the United Kingdom.
ARENA proporcionó un prototipo de prueba para un paradigma de búsqueda que luego adoptaría ARIADNE, basado en un poderoso trío de parámetros: ‘Dónde’, ‘Cuándo’ y ‘Qué’, permitiendo a los usuarios identificar recursos de interés en unos pocos clics. Los socios proporcionaron asignaciones de términos de nivel superior al Tesauro de Tipos de Monumentos MIDAS del Reino Unido y utilizaron sus vocabularios controlados locales para términos de período cronológico (Figura 3). Sin embargo, no se intentó proporcionar una búsqueda temporal utilizando intervalos de tiempo absolutos como Desde y Hasta.
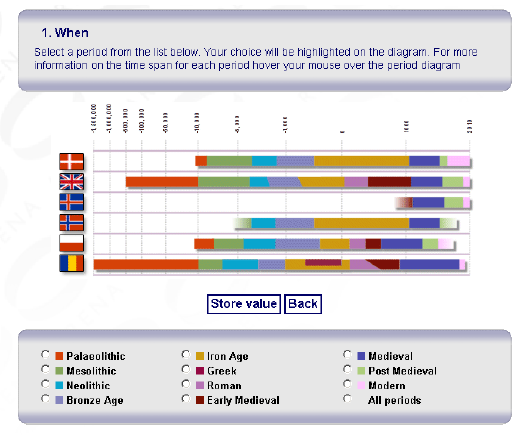
Figure 3: The ARENA temporal search provided a visualisation of the different start and end dates for cultural period terms applied by each of the partners and users could select all resources for which the same period term was used, but searches using absolute date ranges were not possible.
El portal ARENA demostró que era posible realizar búsquedas en linea en múltiples proveedores de datos europeos, pero dependía de tecnologías obsoletas como el protocolo de comunicaciones Z39.50, que se había desarrollado para la búsqueda cruzada en catálogos de bibliotecas. La misma tecnología se había implementado inicialmente para el portal del Reino Unido del catálogo del Servicio de Datos de Artes y Humanidades a fines de la década de 1990 y había sido desarrollada aún más por el Archaeological Data Service (ADS) para el portal del Reino Unido HEIRPORT para Recursos de Información del Entorno Histórico (Austin et al., 2002). En 2009-10, el ADS pudo trabajar con DANS como parte de la fase preparatoria de DARIAH, la Infraestructura de Investigación Digital para las Artes y Humanidades, para migrar el portal ARENA a una arquitectura de servicios web más flexible (Figura 4). ARENA2 cambió el enfoque técnico de ARENA a uno basado en el uso de una Arquitectura Orientada a Servicios (SOA) sobre centros de datos de socios seleccionados para demostrar la viabilidad de utilizar un enfoque SOA en lugar del enfoque original de Z39.50 y la recolección de metadatos de OAI. Un enfoque SOA difiere de los enfoques de recolección de metadatos en que permite el acceso directo y en línea a bases de datos remotas, poniendo los datos más actuales disponibles para ser consultados y minimizando la recolección y gestión de datos por parte del agregador.

La misma infraestructura tecnológica también se utilizó en un proyecto colaborativo entre el ADS y tDAR para construir un Portal de Arqueología Transatlántica (TAG) como buscador de archivos de datos del Reino Unido y Estados Unidos (Jeffrey et al., 2012). La primera etapa fue crear una infraestructura para permitir la búsqueda básica de registros de metadatos compatibles con Dublin Core para recursos digitales que abarcan la arqueología de Estados Unidos y el Reino Unido, con los desafíos adicionales en relación con la periodización y el tipo de tema (Figura 5). La segunda etapa de TAG fue un intento de desarrollar un nivel mucho más profundo y rico de búsqueda cruzada para un subconjunto específico de datos archivados: datos arqueo-faunísticos de América del Norte y Europa. Esta subdisciplina se eligió porque hay un nivel relativamente alto de acuerdo sobre las clasificaciones básicas. El proyecto proporciona un ejemplo temprano del enfoque de perfiles de aplicación que se adoptó posteriormente en ARIADNEplus.

Figure 5: The Transatlantic Archaeology Gateway (2009-11), showing a cross search across the archives of the ADS and tDAR.
Estos primeros demos proporcionaron ejemplos de la escala de las preguntas de investigación que la tecnología podría respaldar. Sin embargo, todos fueron financiados como proyectos de investigación y desarrollo, y aunque hubo apoyo continuo para los repositorios subyacentes a nivel nacional, no hubo una fuente de financiamiento obvia para la infraestructura internacional, y ninguno se encontraba dentro de un marco sostenible. La excepción potencial era Europeana, una iniciativa para reunir de manera virtual las ricas colecciones de museos, galerías y archivos de Europa. El modelo de datos inicial, los Elementos Semánticos de Europeana (ESE), se basaba en el esquema de metadatos Dublin Core y su tratamiento de la cobertura temporal y espacial era inadecuado para el dominio arqueológico (Hansen y Fernie, 2010). En 2010, esto se actualizó al Modelo de Datos de Europeana (EDM), un esquema semánticamente más rico que tiene en cuenta los principios basados en eventos que respaldan el Modelo de Referencia Conceptual CIDOC (CIDOC CRM).
Se financiaron varios proyectos de agregadores y algunos de ellos son discutidos por Vassallo et al. (2023), pero aquellos con un componente arqueológico importante fueron CARARE (2010-13) y LoCloud (2013-16). CARARE se centró en arqueología y arquitectura, con un énfasis adicional en datos 3D (Hansen y Fernie, 2010), mientras que LoCloud enfatizó el contenido local de museos pequeños y medianos. Ambos proyectos adoptaron un subconjunto de la ontología CIDOC CRM como su modelo de metadatos central, aunque solo un subconjunto de esto podía exponerse a través de Europeana. Aunque el portal de Europeana ahora proporciona acceso a más de 50 millones de elementos, su cobertura es tan amplia y su interfaz de búsqueda tan generalizada que es inadecuado para la mayoría de la investigación arqueológica, y no es muy conocido entre los arqueólogos. Como destacó Kilbride (2004): ‘la tecnología no es, por sí sola, la respuesta’.
También hay un creciente interés en los Datos Enlazados Abiertos en arqueología, proporcionando mecanismos para la agregación de datos, incluyendo servicios como Pleiades (un gazetteer comunitario de lugares antiguos) y Pelagios (también conectando lugares en el mundo clásico), que se centran en enfoques geoespaciales para la interoperabilidad de datos (Isaksen et al., 2014). Asimismo, debemos tener en cuenta la implementación de enfoques de Datos Enlazados Abiertos por parte de Open Context (Kansa, 2014). Se presenta como una plataforma de publicación de datos basada en la web en lugar de un agregador de datos, aunque en 2012 se utilizó la misma arquitectura técnica para desarrollar la plataforma Digital Index of North American Archaeology (DINAA), que agrega conjuntos de datos arqueológicos e históricos en su mayoría recopilados de agencias gubernamentales estatales y federales, y proporciona acceso a más de 880,000 registros a través de una interfaz basada en mapas. La naturaleza distribuida de los Datos Enlazados Abiertos también lo convierte en un mecanismo adecuado para la agregación de datos que abarcan varios dominios, con datos gestionados y curados por especialistas en el dominio y la creación de interfaces adaptadas que reflejen conjuntos específicos de necesidades de los usuarios. Varios proyectos financiados dentro del programa Towards a National Collection del Reino Unido han explorado el uso de Datos Enlazados Abiertos (LOD) como la única solución viable para proporcionar vistas de datos nacionales.
ARIADNE proporciona un nuevo capítulo en la historia de la agregación de datos arqueológicos y es el enfoque principal de este artículo. Financiado por el programa de infraestructura de investigación de la Comisión Europea, tuvo como objetivo proporcionar acceso unificado a datos arqueológicos procedentes de varios países de una manera que permitiera a los investigadores abordar nuevas preguntas. ARIADNE buscó aprender de lecciones pasadas al regresar al enfoque arqueológico de ARENA y enfatizar un proceso de mapeo impulsado por las necesidades de los usuarios de investigación arqueológica. Ha desarrollado un potente portal de búsqueda cruzada, basado en Datos Enlazados Abiertos (Aloia et al., 2017; Meghini et al., 2017; Richards y Niccolucci, 2019). Lograr la interoperabilidad entre diferentes idiomas y culturas europeos es un desafío, y la adhesión a estándares de datos es esencial para cualquier nivel de interoperabilidad semántica y búsqueda cruzada. En ARIADNE, los términos nacionales del tema se han mapeado a un estándar central común (en este caso, el Tesauro de Arte y Arquitectura Getty) y los términos arqueológicos de período se han definido según criterios explícitos, trabajando con la iniciativa norteamericana PeriodO (Shaw et al., 2016).
Agregación de Datos en ARIADNE
ARIADNE ha agregado recursos de más de 45 proveedores de datos, abarcando más de 40 países y cuatro continentes. A partir de mayo de 2023, el portal de ARIADNE proporciona acceso en línea a más de 3.9 millones de recursos de investigación, y este número sigue aumentando. El portal se basa en un almacén triple gestionado en Graph DB. En el momento de la redacción, el triple store (almacén de RDF) utilizado por el portal público consta de 322,218,928 triples.
La Infraestructura de Investigación ARIADNE se desarrolló durante el primer proyecto ARIADNE, con financiamiento de la Comisión Europea, en el marco del Programa Marco 7 para el período 2013-2017. El objetivo de ARIADNE era proporcionar acceso abierto al patrimonio arqueológico de Europa y superar la fragmentación de los repositorios digitales, ubicados en diferentes países y compilados en diferentes idiomas (Niccolucci y Richards, 2019). Técnicas innovadoras de mapeo de vocabulario aportaron interoperabilidad a una colección enorme y heterogénea de textos, dibujos, imágenes, videos, modelos 3D y mapas. Al final del proyecto ARIADNE original, habíamos logrado catalogar aproximadamente 1.9 millones de conjuntos de datos arqueológicos, utilizando el Modelo de Datos Común de ARIADNE (ACDM) (Figura 6) (Aloia et al., 2017).

Figure 6: Screen shot of the original ARIADNE portal. The landing page provided a free text search box and the opportunity to browse the catalogue by the three key parameters of Where, When and What.
En 2019, comenzamos el trabajo en la segunda iteración de ARIADNE, con un consorcio ampliado y financiamiento de Horizon Europe. El modelo de datos fue revisado y simplificado, adoptando también algunas lecciones del proyecto PARTHENOS, y se lanzó como el AO-Cat (Felicetti et al., 2023). Nos interesaba no “hacer un gran montón+” de todos los datos y, aprendiendo de proyectos anteriores de agregación de datos, definimos una ontología revisada, el AO-Cat, como un subconjunto del CIDOC CRM como una ontología estricta, y también prestamos mucha atención a los estándares de datos y vocabularios controlados para lograr un alto nivel de interoperabilidad. El catálogo se migró de una estructura de base de datos tradicional a un triple store de Linked Open Data, evitando la creación de otro silo de datos y abriendo la Base de Conocimientos para la vinculación desde y hacia otros recursos en línea.
ARIADNEplus ha reunido un conjunto de registros mucho más amplio que el proyecto predecesor ARIADNE, sobre cuyo éxito ha podido construir (Figura 7). La intención fue integrar conjuntos de datos que abarcaran ampliamente en espacio y tiempo, y a través de un rango más amplio de subdominios arqueológicos. Al final del proyecto financiado, tenemos 7,710 recursos que datan de antes de 1,000,000 aC, y 517,535 recursos que datan después del año 1900 dC, demostrando el alcance completo de la investigación arqueológica del siglo XXI. Tenemos recursos de América del Norte y del Sur, Europa y Escandinavia, y Asia. Los datos integrados cubren todos los tipos de recursos de ARIADNE, desde inscripciones y arte rupestre hasta análisis científicos y recursos de datación. Hemos integrado más de un millón de registros para sitios y monumentos individuales, más de 855,250 artefactos y 470,000 monedas. Nuestro catálogo incluye más de 290,000 informes de trabajo de campo inéditos y más de 110,000 archivos completos de trabajo de campo. Estos representan una enorme infraestructura de investigación digital ahora disponible de manera gratuita y fácil como datos de acceso abierto para científicos e investigadores europeos, profesores y estudiantes, así como para miembros interesados del público.
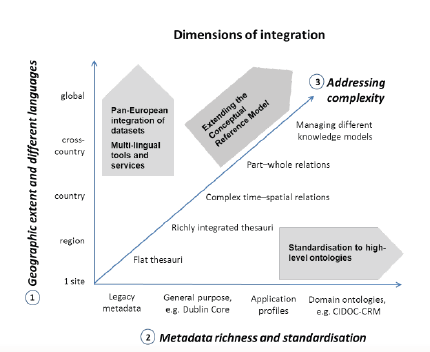
Figure 7: The ARIADNE approach for addressing the complexity of developing advanced integrated services for archaeological research communities.
La tarea de agregación será ahora sostenida a través del trabajo de la ARIADNE Research Infrastructure AISBL, una asociación sin fines de lucro registrada bajo la ley belga, pero que opera a nivel internacional. Actualmente, opera bajo un modelo de suscripción mediante el cual los miembros pueden pagar una tarifa anual para actualizar y agregar sus recursos en línea. En este sentido, es importante señalar que ARIADNE es tanto una comunidad como una infraestructura técnica. Las infraestructuras de investigación en línea pueden actuar como catalizadores para reunir a diferentes comunidades de experiencia e interés, y ARIADNE ha creado un ecosistema académico, así como un portal (ver Benardou et al. 2017; Wright y Richards 2018).
La ontología ARIADNE
La Ontología ARIADNE, AO por sus siglas, fue desarrollada al inicio del proyecto ARIADNEplus con el propósito de integrar los datos arqueológicos de los socios de ARIADNE en un espacio de información común. Basándose en proyectos anteriores, el CIDOC CRM, la ontología estándar en el dominio del patrimonio cultural, fue adoptado como la columna vertebral conceptual de AO, proporcionando un marco lingüístico y axiomático unificado y coherente. Posteriormente, el CRM se especializó, bajo un espacio de nombres especialmente diseñado para satisfacer las necesidades de los diferentes subdominios abordados por el proyecto ARIADNEplus. La primera de esas especializaciones fue el AO-Cat, la parte de AO que se ocupa de la representación de los recursos en el Catálogo ARIADNE. El AO-Cat se utilizó para construir el Catálogo ARIADNE. La segunda ronda de especializaciones se conoce como perfiles de aplicación, que se han desarrollado para respaldar la integración de datos más especializados a nivel de ítem de los socios de ARIADNE en la Base de Conocimientos ARIADNE.
El Catálogo ARIADNE proporciona una representación a nivel de colección de los recursos compartidos por los socios del proyecto. Sin embargo, aunque la distinción entre nivel de colección y nivel de ítem puede parecer obvia, se puede aplicar de muchas maneras, según cómo definamos lo que consideramos que son ítems. Esto, a su vez, depende del contexto de investigación específico y de la pregunta de investigación. Por ejemplo, a nivel de investigación de paisajes, cada sitio arqueológico puede considerarse un ítem de observación, y el registro a nivel de colección se refiere a la base de datos de sitios y monumentos nacionales, mientras que para un estudio basado en artefactos, los objetos individuales pueden ser los ítems de interés, y el registro a nivel de colección se refiere ahora a la base de datos de artefactos, potencialmente de varios sitios.
En la primera fase de ARIADNE, produjimos un catálogo que ya incluía registros de metadatos resumidos para sitios y monumentos arqueológicos a nivel de ítem y este enfoque se mantuvo en ARIADNEplus. También se realizaron experimentos en una integración más granular a nivel de ítem, investigando especialmente la interoperabilidad entre varias bases de datos de monedas mantenidas por diferentes socios (Felicetti et al., 2015). En ARIADNEplus, estos desarrollos se extendieron mediante la adopción de perfiles de aplicación.
Los Perfiles de Aplicación son modelos ontológicos particulares cuyo propósito es describir la información relacionada con un dominio de investigación específico de manera coherente y completa. La filosofía detrás de la definición de un Perfil de Aplicación es la de reutilizar los elementos de ontologías y modelos existentes para la descripción de entidades similares en el nuevo contexto de investigación, limitando el desarrollo de nuevos elementos solo para la descripción de aspectos peculiares y típicos de la disciplina específica. En ARIADNEplus, por ejemplo, seleccionamos clases de la ontología CIDOC CRM y del estándar Dublin Core para definir perfiles de aplicación para la descripción de datos científicos y datos mortuorios a nivel de ítem. Sin embargo, vale la pena señalar que el AO-Cat es en sí mismo un perfil de aplicación para lo que podríamos considerar observaciones arqueológicas de un nivel superior. Captura la información básica de ‘Qué’, ‘Cuándo’ y ‘Dónde’ que impulsa la interfaz de búsqueda del portal, y proporciona una representación adecuada para el descubrimiento de recursos relacionados con sitios y monumentos arqueológicos. También ha quedado claro que proporciona información básica adecuada para otros subdominios donde ‘Qué’, ‘Cuándo’ y ‘Dónde’ capturan los metadatos y datos principales, como en el caso de artefactos arqueológicos, por ejemplo. En otros casos, puede proporcionar un registro a nivel de colección para clases relacionadas de datos, como análisis científicos, aunque pueda necesitarse un perfil de aplicación para abordar las preguntas de investigación específicas del subdominio. La tarea de crear perfiles de aplicación se delegó a grupos de interés especiales de especialistas en subdominios. Las actividades y las discusiones de los grupos de trabajo han demostrado que, en muchos casos, el AO-Cat es suficiente, sin necesidad de modificaciones adicionales, para cubrir las necesidades de sus subdominios, incluso para la agregación de datos a nivel de ítem. También es notable que la adición de una gran colección de recursos al Catálogo durante la vida útil de ARIADNEplus no ha requerido ningún cambio en la ontología. Esto indica que el AO-Cat ha alcanzado un nivel maduro de estabilidad y, por lo tanto, está listo para un uso más amplio fuera de los límites del proyecto ARIADNEplus. De hecho, en el Reino Unido, el AO-Cat ha sido adoptado con pocas modificaciones por Unpath’d Waters, un proyecto importante para caracterizar y agregar datos digitales sobre el rico patrimonio marítimo del Reino Unido.
Mapeo de Datos
Habiendo diseñado el AO-Cat como una ontología compartida, la interoperabilidad dependía del mapeo de los modelos de datos de conjuntos de datos heterogéneos de los socios al AO-Cat. Para esto se utilizó la X3ML Toolkit desarrollada por FORTH. La X3ML Toolkit es un conjunto de microservicios pequeños, de código abierto, que siguen el Modelo de Referencia SYNERGY para la provisión y agregación de datos. Nos permitió definir equivalencias entre los diversos atributos en los datos proporcionados por los socios con propiedades en el AO-Cat. Sin embargo, para facilitar una búsqueda cruzada útil, también era esencial lograr la interoperabilidad de los metadatos utilizados para describir las tres facetas principales de Dónde, Cuándo y Qué. Para respaldar una búsqueda cruzada efectiva de metadatos originarios de muchos países diferentes, se requiere cierto entendimiento común compartido del significado de los metadatos. Las facetas ‘Dónde’ y ‘Cuándo’ pueden comunicarse utilizando tipos de datos comunes y valores comparables (por ejemplo, coordenadas espaciales relativas a una ubicación conocida en la Tierra, rangos de fechas relativos a una época conocida). La faceta ‘Qué’ (sujeto) puede ser más difícil de definir en un formato comúnmente entendido y comparable.
Tesauro de Arte y Arquitectura de Getty
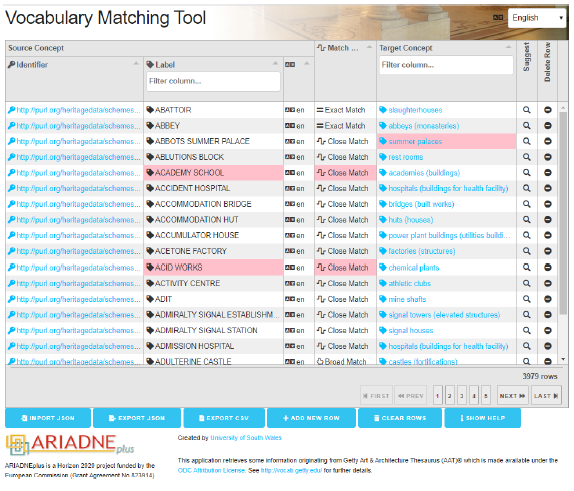
En lugar de intentar mapear cada vocabulario de temas con todos los demás vocabularios de temas, se acordó mapear cada vocabulario a una columna vertebral común (Binding et al., 2015). El Tesauro de Arte y Arquitectura de Getty (AAT) proporciona conceptos y términos para describir conceptos del patrimonio cultural. El AAT está disponible como Datos Enlazados Abiertos, por lo que cada concepto en el tesauro tiene un identificador único en forma de un URI (por ejemplo, http://vocab.getty.edu/aat/300211545 es el identificador del concepto “broches penannulares”). ARIADNE adoptó el AAT como un centro central para la interconexión escalable de vocabularios locales de temas. Se requirió que los proveedores de datos proporcionaran un conjunto de mapeos, desde su propio vocabulario local de temas (todos los términos utilizados para describir temas en sus propios metadatos) hasta el AAT, y se desarrolló una herramienta de mapeo de vocabulario para facilitar este proceso (Figura 8). El objetivo del ejercicio de mapeo de temas era mejorar la recuperación y precisión al navegar y buscar posteriormente los datos por tema. Sin embargo, uno de los problemas a los que se enfrentaron fue que para varios países no existía un vocabulario de temas acordado. En estos casos, los socios a menudo llevaron a cabo un extenso ejercicio de mejora de datos, adoptando el AAT desde el principio. Para otros, esto no fue posible, pero se decidió incluir sus datos en la agregación, siempre y cuando aún fueran encontrables por las facetas de Cuándo y Dónde.
PeriodO
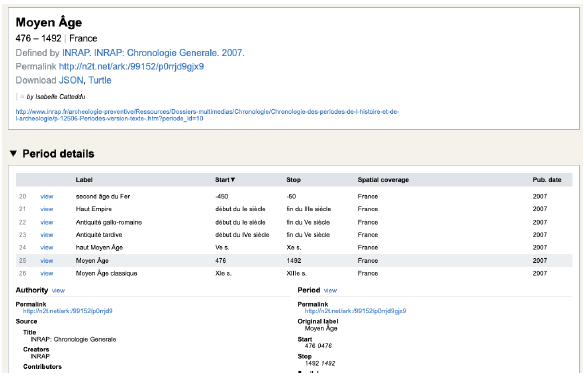
PeriodO es un gacetero multilingüe de definiciones de periodos históricos y arqueológicos para describir periodos con nombres. Incluye una serie de ‘autoridades’ (listas de periodos con nombres) donde cada definición de periodo individual está asociada con una área geográfica específica, una fecha de inicio y una fecha de finalización. Los periodos y autoridades tienen identificadores de ‘permalink’ (URIs) para que puedan ser referenciados de manera clara y unívoca, por ejemplo, el identificador http://n2t.net/ark:/99152/p0rrjd9gjx9 define el periodo ‘Moyen Âge’ (Edad Media) dentro de la autoridad http://n2t.net/ark:/99152/p0rrjd9 ‘INRAP: Chronologie Generale. 2007’ (Figura 9). Todos los periodos con nombres en ARIADNE se han definido con referencia a periodos dentro de PeriodO.
**PeriodO** en ARIADNE se utiliza en una etapa posterior de enriquecimiento de datos con un propósito diferente al uso del enriquecimiento de datos con AAT; en lugar de alinear datos con identificadores comunes, PeriodO se utiliza en una etapa posterior de enriquecimiento de datos para mejorar los registros que ya se han indexado con periodos con nombres (como “Edad de Bronce”, “Edad de Hierro”, etc.), donde las fechas asociadas con estos periodos no se hacen explícitas en los datos de entrada, proporcionando fechas de inicio/fin para que estos registros sean comparables y encontrables de la misma manera que otra información de fecha.
Nuevamente, hubo casos en los que los nombres de los periodos no estaban disponibles, aunque a veces los proveedores ya tenían fechas de inicio y fin para sus recursos, por lo que se podía pasar por alto la mejora de PeriodO. En algunos casos, sin embargo, no se disponía de datos temporales, pero los recursos se incluyeron si eran descubribles a través de los otros aspectos fundamentales.
Datos Geográficos
Para abordar la dimensión espacial, todas las coordenadas espaciales en ARIADNE se expresan utilizando el Sistema Geodésico Mundial 1984 (WGS84). Este es un sistema de coordenadas geográficas estándar que comprende un datum horizontal y vertical global, así como un sistema de coordenadas utilizado (especialmente por sistemas de GPS) para expresar la posición global en la superficie de la Tierra. Para los propósitos de ARIADNE, todas las coordenadas espaciales se expresan utilizando WGS84. Las coordenadas en conjuntos de datos locales a veces requerían normalización/transformación antes de la agregación para mejorar las oportunidades de búsqueda cruzada de los conjuntos de datos integrados. Las coordenadas WGS84 se expresan en grados: la posición horizontal es la longitud (con valores entre -180° y +180°, en relación con un datum fijo de 0° en Greenwich, Reino Unido) y la posición vertical es la latitud (con valores entre -90° y +90°, en relación con un datum fijo de 0° en el ecuador). Como ejemplo, la ubicación global de la Torre Inclinada de Pisa (Torre di Pisa) se da mediante las coordenadas WGS84 de latitud 43.723056 (43° 43’ 23’’ N) y longitud 10.396389 (10° 23’ 47’’ E).
El flujo de trabajo de agregación
A los socios se les ofrecieron dos opciones para la agregación: el enfoque estándar que utiliza un conjunto de herramientas para la agregación semiautomática de conjuntos de datos grandes, y un enfoque básico para la carga manual de pequeños números de registros. La mayoría de los socios utilizó el enfoque estándar, pero un pequeño número utilizó FastCat, una herramienta proporcionada para la carga de unos pocos registros. Esto también resultó invaluable para la adición de registros de colecciones personalizadas para recursos recolectados.
Los socios que siguieron el enfoque estándar tuvieron que:
1. Describir sus datos según el AO-Cat utilizando la herramienta X3ML, generalmente con un mapeo, por socio.
2. Mapear los términos de sujetos al Getty AAT utilizando la Herramienta de Coincidencia de Vocabulario.
3. Definir cualquier término temporal utilizado para que se cargue en PeriodO.
Cuando los datos temporales necesitaban limpieza para crear un uso consistente de rangos de fechas y períodos, los socios utilizaron una herramienta adicional, Yearspans, para normalizar los rangos de fechas (Binding y Tudhope, 2023). También tuvieron que asegurarse de que sus datos espaciales fueran compatibles con WGS84.
Los socios que utilizaron FastCat en su lugar introdujeron manualmente sus registros de datos en la herramienta tipo hoja de cálculo, donde los encabezados de las columnas ya correspondían a los campos obligatorios básicos de AO-Cat, de modo que podría haber un solo mapeo X3ML que cubriera a varios socios.
Los proveedores de datos suministraron sus datos a ARIADNE ya sea como volcados de datos XML o JSON o, cuando se requerían actualizaciones regulares, se prefería la alimentación OAI-PMH. Luego, los datos se convirtieron en la ontología AO Cat como archivos RDF y se almacenaron en la base de conocimientos ARIADNEplus (basada en la tecnología GraphDB). Los datos suministrados podrían incluir mapeos al Getty AAT o PeriodO, o estos podrían agregarse a la base de conocimientos en esta etapa de agregación de datos (Figura 10). Desde aquí, los recursos de datos de ARIADNE se pueden reutilizar para múltiples propósitos, por ejemplo, en portales o en VRE, o por consumidores externos, evitando la creación de un silo de datos. La base de conocimientos también facilita la vinculación con fuentes externas de Datos Abiertos Vinculados, como Wikidata (Figura 11). Los datos se publicaron primero en un portal de ensayo, para permitir una verificación de calidad, antes de su liberación en el portal público.
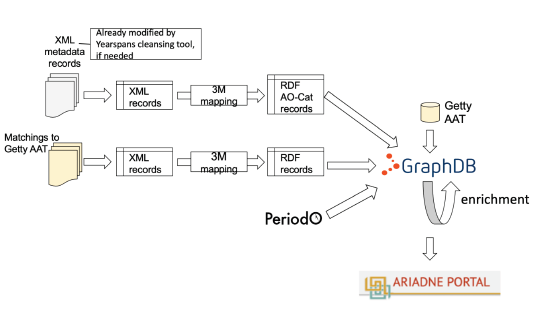
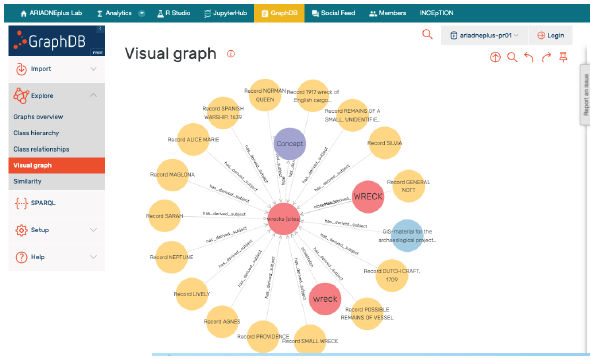
Uso del Portal ARIADNE para investigación arqueológica y gestión del patrimonio
Parte de la fortaleza del portal ARIADNE se encuentra en índices que se localizan en ese triple almacenamiento y ofrecen un medio rápido y efectivo de filtrar la Base de Conocimientos. Inicialmente, se implementaron en Elastic Search, pero se migraron a Open Search para mantener el énfasis en el software de código abierto; ofrecen una potente instalación de navegación por partes. Reflejando su origen y trayectoria en Dublin Core, el AO-Cat permite la definición de varios agentes asociados con un recurso de datos: Creador, Colaborador, Propietario, Editor, Responsable Científico. Estos pueden ser individuos u organizaciones. En muchos casos, la mayoría de los agentes declarados por los proveedores de datos eran la misma entidad, pero la variedad de agentes posibles permitía la atribución de una amplia gama de roles. Dado que Editor y Colaborador tenían filtros en la interfaz del portal, estos eran los más importantes, y uno de los desafíos del proceso de agregación fue asegurar que las categorías se aplicaran de manera consistente. Así, AO-Cat definía al Editor como el agente (generalmente el proveedor de datos o socio) responsable de publicar los metadatos en línea, mientras que el Colaborador era generalmente el mismo que el Propietario o Creador (Figura 12).
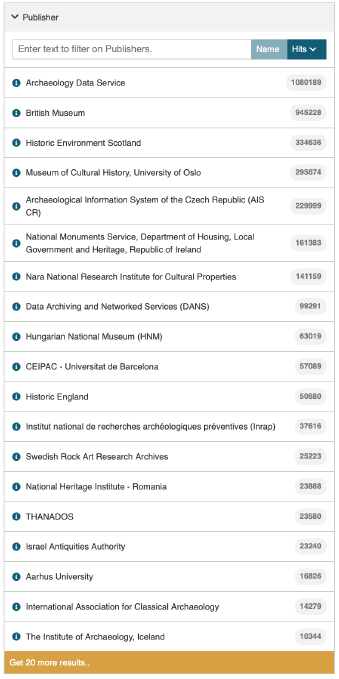
Figure 12: The Publisher filter in the ARIADNE portal. This provides a rapid identification of the number of records from each provider, and in many cases also acts as a country search.
De igual importancia es el filtro “Tipo de Recurso”. Esto es efectivamente una especialización de la categoría Qué o Sujeto, extraída de una lista corta de 13 categorías predefinidas. Aunque los términos pueden asignarse al AAT más amplio, proporcionan un conjunto pragmático de tipos de recursos que se definieron “de abajo hacia arriba” según los tipos más comunes de datos proporcionados por los socios. Nuevamente, la coherencia en la aplicación fue importante, pero el filtro proporciona un medio efectivo para definir el nivel de detalle requerido en una búsqueda (Figura 13). Los registros dentro de un “Tipo de Recurso” tienden a ser más homogéneos que entre ellos, asegurando un mayor grado de interoperabilidad dentro de las categorías. Si más proveedores se unieran a ARIADNE RI, las categorías son capaces de extenderse, aunque esto podría tener implicaciones para la necesidad de volver a categorizar colecciones existentes. También dependen del nivel de información proporcionado. Por lo tanto, fue relativamente fácil distinguir entre las 470,677 monedas y los 474,552 artefactos proporcionados por el Portable Antiquities Scheme (PAS) del Museo Británico, y algunos proveedores de datos, como el RGK, solo proporcionaron información sobre monedas, pero para la base de datos DIME de Dinamarca, los registros de monedas estaban integrados en el conjunto de datos más amplio.
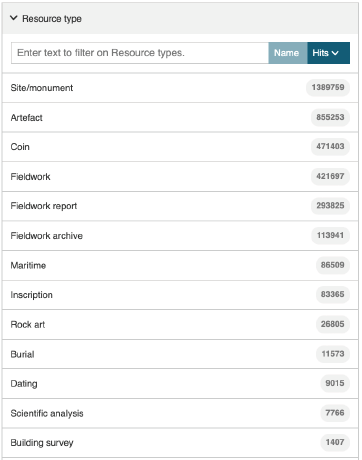
Figure 13: The Resource Type Filter in the ARIADNE portal allows users to extract a subset of interoperable data.
La colaboración con THANADOS, una base de datos antropológica y arqueológica austriaca de cementerios y tumbas, proporciona un ejemplo especialmente bueno del valor de los tipos de recursos. El modelo de datos de THANADOS proporciona información en cuatro niveles: cementerio, tumba, entierro y artefacto, y esto se refleja en el perfil de aplicación de ARIADNE para datos mortuorios (Aspöck et al., 2023). El mapeo de AO-Cat permite el uso de los tipos de recursos de ARIADNE ‘Sitio/monumento’, ‘Entierro’ y ‘Artefacto’ para reflejar la estructura relacional de la base de datos de THANADOS, lo que permite a los usuarios filtrar según el nivel de detalle que les interese. A su vez, el perfil de aplicación mortuoria se puede utilizar para codificar los detalles de cada uno de los aspectos únicos de esta actividad arqueológica.
Para búsquedas más detalladas basadas en el tema, el uso del AAT como vocabulario central ha sido muy efectivo, y la Herramienta de Mapeo de Vocabulario ha permitido a los socios realizar el mapeo de manera relativamente fácil. Aunque el tesauro de Getty no define términos equivalentes en todos los idiomas, permite un nivel de búsqueda multilingüe. Habiendo especificado una búsqueda de términos de tema AAT, por ejemplo, los usuarios pueden ingresar ‘Swords’ (inglés), ‘Zwaarden’ (neerlandés), ‘Épée’ (francés), ‘Spada’ (italiano) o ‘Espadas’ (español) y obtener los mismos resultados (Figura 14). Además, siempre que el proveedor haya mapeado su término en su idioma nativo para el equivalente al concepto ‘Swords’ en el AAT de Getty, también se recuperarán sus registros. La búsqueda también utiliza su diccionario para proporcionar una función de autocompletar como una ayuda adicional para el investigador.
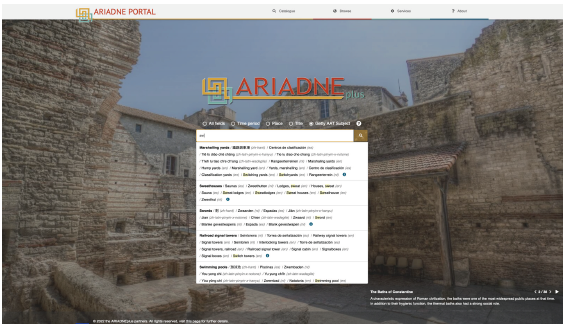
Figure 14: The ARIADNEplus portal landing page, showing the autocomplete and multilingual features provided by the application of the Getty AAT.
La potencia del jerárquico AAT de Getty también se demuestra por la capacidad del usuario para encontrar objetos definidos a través de términos más estrechos, incluso si el término más amplio no se ha incluido en los metadatos (Figura 15). Por lo tanto, una búsqueda de ‹Swords’ también recupera ‘Cutlasses’, ‘Foils’, ‘Rapiers’ y cualquiera de las 22 categorías más estrechas. En algunos casos, el AAT de Getty no llegaba al nivel de detalle que los investigadores podrían desear, por ejemplo, en tipos detallados de broches o monedas, aunque donde hay respaldo y autoridad de dominio, se podría hacer un caso futuro para extender el tesauro para uso especializado.
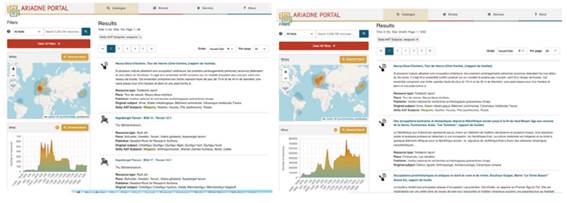
Figure 15: A searching on “weapons” without narrower terms (left) yields only 753 resources, whereas when narrower terms are included (right) 24,834 resources are retrieved.
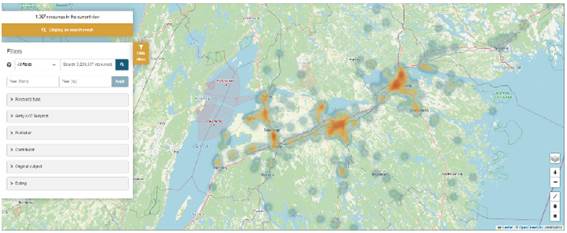
Una de las características más populares y utilizadas de la interfaz del portal ha resultado ser la búsqueda basada en mapas (Figura 16). El mapa de calor proporciona una visualización rápida de la densidad de registros, pero se resuelve en puntos y polígonos individuales que se pueden hacer clic a medida que el investigador utiliza la función de zoom. Las herramientas adicionales incluyen la opción de utilizar diferentes bases de mapas y buscar a través de un cuadro delimitador o un polígono definido por el usuario. El menú proporciona los mismos filtros disponibles en la página principal de resultados, lo que permite a los usuarios seleccionar registros específicos de interés.
El soporte para polígonos se incorporó en el AO-Cat, ya que estos pueden ser importantes para mostrar la extensión completa de sitios arqueológicos o áreas de trabajo de campo. Los polígonos se ven mejor en los mapas incluidos en las páginas de inicio de registros individuales (Figura 17), que también ofrecen la opción de ver recursos cercanos. Los metadatos mostrados en las páginas de inicio de recursos individuales generalmente también proporcionan enlaces a la página de inicio del recurso principal. Esto es de considerable importancia, ya que los enlaces pueden dar acceso a información mucho más rica y detallada, incluidos informes de texto descargables y, en algunos casos, archivos digitales completos en línea. Idealmente, el enlace debería ser a través de identificadores permanentes, como Identificadores de Objetos Digitales (DOIs), contribuyendo a que el portal proporcione acceso a datos justos y accesibles. Esto también proporciona una importante función tipo “vitrina” para los proveedores de datos, atrayendo a los investigadores a sus propios sitios web, de los cuales podrían no haber tenido conocimiento previamente. En algunos casos, sin embargo, los datos se han publicado en línea por primera vez a través del portal ARIADNE, y no hay información adicional para enlazar.
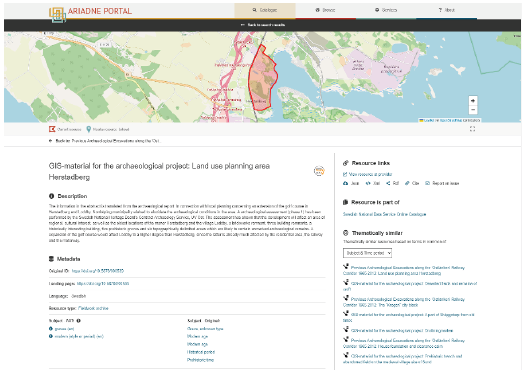
Figure 17: Landing page for an individual data resource, illustrating the ability to display the geospatial extent of the resource as a polygon.
La función de exploración temporal proporciona una funcionalidad equivalente para la faceta “Cuándo”. Permite una visualización rápida del rango temporal de los recursos seleccionados, lo que proporciona una valiosa herramienta de investigación por derecho propio, pero el uso de PeriodO para definir rangos en años absolutos también permite al usuario seleccionar un lapso de tiempo específico de interés y ver los resultados. (Figura 18). Una segunda opción, agregada durante el proyecto, permite filtrar por períodos de tiempo, según las regiones temporales seleccionadas. Por ejemplo, esto permite al usuario seleccionar sitios clasificados según la etiqueta cultural Edad del Hierro en diferentes regiones temporales, independientemente de las fechas Desde y Hasta de la Edad del Hierro en esas regiones.
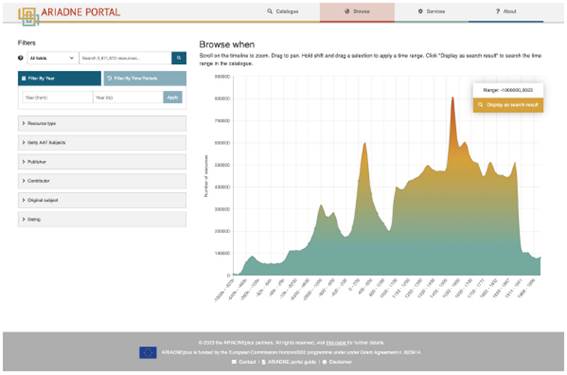
La ontología AO-Cat demostró ser adecuada para las necesidades de la mayoría de los proveedores de datos durante la vida del proyecto, y solo se requirieron extensiones en dos áreas. La primera surgió del deseo de incluir imágenes entre los metadatos mostrados en las páginas de destino de los recursos, y miniaturas dentro de la lista de resultados. Esto surgió especialmente de los investigadores de artefactos que querían poder comparar objetos individuales (Figura 19). Claramente, esto también podría mejorarse utilizando el Marco Internacional de Interoperabilidad de Imágenes (IIIF) y visores apropiados en un proyecto futuro.
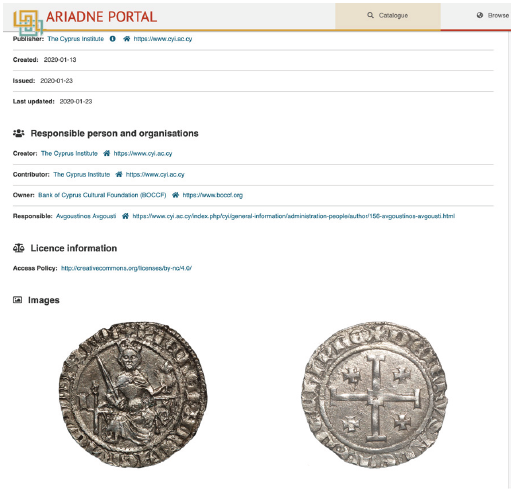
Figure 19: The landing page for a coin held by the Bank of Cyprus Cultural Foundation showing the value of including images amongst the metadata harvested by the portal.
La segunda necesidad de una extensión al AO-Cat surgió porque algunos proveedores de datos pidieron incluir información sobre la región espacial cubierta por un recurso de datos, con una especificación sobre la precisión de la información. Esto se debió a dos razones principales. En primer lugar, en algunos casos, el proveedor de datos solo tenía datos de la ubicación del sitio a un nivel impreciso, por lo que era necesario dejar claro, al representar ubicaciones en un mapa, que el punto podría representar la ubicación del sitio hasta un nivel cercano a 10 km, por ejemplo. Una vez que esto se codificó dentro del AO-Cat y los datos se almacenaron en el triple sistema, el portal lo manejó utilizando una simbología diferente. En segundo lugar, había casos en los que el proveedor de datos tenía datos espaciales sensibles que no deseaban hacer públicos, tal vez para proteger la ubicación precisa de un sitio. En estos casos, se suministraron datos espaciales a la resolución que estaban dispuestos a hacer disponibles, y la ubicación se representó como un cuadro delimitado, que incluía el punto de hallazgo real en algún punto aleatorio. Por ejemplo, los datos espaciales para la base de datos del PAS del Reino Unido se suministraron con un cuadro delimitador de 1 km o 10 km, según la sensibilidad del lugar de hallazgo (Figura 20).
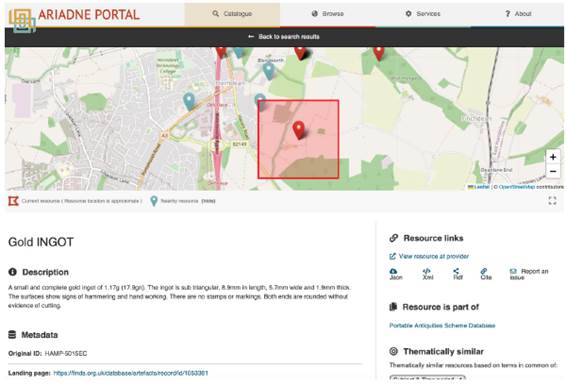
Figure 20: The location of the find spot of a gold ingot displayed to a 1km resolution, such that the actual find spot may be anywhere within the red bounding box.
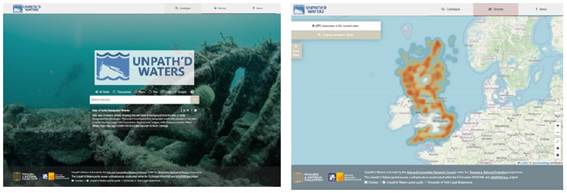
Finalmente, la base de conocimientos ARIADNE y la arquitectura del portal permiten adaptarse fácilmente para proporcionar una amplia gama de interfaces más especializadas. Por ejemplo, como parte del proyecto “Towards a National Collection Unpath’d Waters”, el ADS pudo desarrollar un portal que ofrece una búsqueda cruzada distribuida de las muchas agencias que tienen datos sobre el patrimonio marítimo de las aguas costeras del Reino Unido mediante la implementación de una instancia del portal ARIADNE (Figura 21). En este caso, la búsqueda estaba “cableada” para limitarla a aquellos recursos para los cuales el Tipo de Recurso era ‘Marítimo’, y para que solo se recuperaran registros de proveedores de datos del Reino Unido. Dado que la fuente de metadatos es el almacenamiento triple de ARIADNE RI, los metadatos se almacenan solo una vez, y los recursos agregados para el proyecto Unpath’d Waters aparecen simultáneamente en el portal de ARIADNE, proporcionando así una vista europea del conjunto de datos del Reino Unido. El enfoque podría ampliarse en cualquier dirección, por ejemplo, proporcionando vistas nacionales para agencias que no desean (o no tienen la capacidad) de desarrollar su propia interfaz de búsqueda, evitando la duplicación, o para vistas temáticas de datos, a nivel internacional.
Conclusión
En conclusión, el portal ARIADNE proporciona acceso al conjunto de datos arqueológicos en línea más grande a nivel internacional, y no hay nada comparable en otras disciplinas de Artes y Humanidades. Sin embargo, es esencial tener en cuenta que el papel del servicio de agregación de ARIADNE no es duplicar los servicios ya disponibles en los sitios web de los proveedores de datos, sino proporcionar interoperabilidad y descubrimiento de recursos a través de múltiples fuentes. No obstante, en algunos casos, el portal proporciona una herramienta de investigación poderosa por sí misma (Richards, 2023). El servicio se construyó sobre las bases establecidas por varios proyectos anteriores, pero se han aprendido lecciones adicionales. En primer lugar, para desarrollar una búsqueda cruzada útil, es evidente que el uso consistente de una ontología es esencial. El CIDOC CRM era lo suficientemente amplio como para abarcar todos los subdominios involucrados, pero era importante realizar un mapeo consistente, y el desarrollo de perfiles de aplicación liderados por la comunidad fue esencial en este sentido. En segundo lugar, para lograr la interoperabilidad, el control del vocabulario también es esencial, y tuvimos la suerte de poder basarnos en décadas de inversión en estándares de datos y tesauros en arqueología. El Getty AAT proporcionó una columna vertebral común potente, pero los mapeos requieren supervisión nuevamente para garantizar la consistencia en los mapeos de los socios. En tercer lugar, es esencial darse cuenta de que, al tratar con datos tan heterogéneos, es imposible hacer que todo sea interoperable, y es necesario considerar el papel de la agregación y cómo los investigadores utilizarán los datos. En ARIADNE, basándonos en proyectos anteriores, Que, Cuando, Donde resultó ser extremadamente efectivo, aunque a posteriori Quién también podría haber sido útil, especialmente si el portal se extendiera para incluir más informes y libros escritos por individuos. Sin embargo, actualmente carecemos de listas de autoridades que nos permitan definir a las personas. Una mayor adopción de identificadores ORCID podría ofrecer una solución para personas en la actualidad, pero necesitamos examinar las soluciones e identificadores ofrecidos por Wikidata para tratar con personas del pasado.
Por sobre todo, nuestro trabajo en la agregación de datos ha destacado la importancia de equipos interdisciplinarios en este esfuerzo y la necesidad de que los arqueólogos trabajen en estrecha colaboración con científicos de la información. Es necesario tomar decisiones clave sobre los niveles de detalle o granularidad y las escalas de la agregación de datos, y qué es útil agregar a nivel de ítem, o dónde tiene sentido agregar solo a nivel de colección. En este sentido, nuestro enfoque debe ser impulsado por la investigación y las preguntas de los investigadores y especialistas de este campo.