











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkIntroducción
El dimensionamiento adecuado de estructuras hidráulicas requiere el conocimiento de los caudales máximos que debe soportar la estructura (Cashalo et al, 2017). En la estimación de caudales de diseño, cuando no se dispone de una estación de aforos en el lugar de análisis donde debe diseñarse una obra, suelen utilizarse modelos de transformación de lluvia-caudal, a los efectos de obtener los caudales picos de diseño, en base a una determinada tormenta de diseño (Danill et al., 2005). La precisión de los resultados de los modelos depende de la calibración y la validación.
Uno de los principales problemas que se presentan en el diseño de las obras hidráulicas, en la provincia Entre Ríos, es la falta de información para realizar una correcta estimación del caudal de diseño. En muchos casos es difícil ejecutar la calibración de un modelo hidrológico debido a la escasez de estaciones de aforo, esto trae como consecuencia errores en la precisión de los caudales de diseño. Muchas obras hidráulicas ejecutadas correctamente pueden fallar por la ocurrencia de caudales que superan los estimados, generando inundaciones o roturas, con las consecuentes pérdidas económicas. Por el contrario, en otros casos se puede llegar a un sobredimensionamiento de las obras debido a una sobrestimación de los caudales de diseño.
Una posibilidad para disminuir la incertidumbre en los caudales máximos estimados en cuencas no aforadas es recurrir a técnicas de regionalización.
El término regionalización se utiliza en Hidrología para denominar la transferencia de información de un sitio a otro dentro de un área de comportamiento hidrológico semejante (Tucci, 2007). Así, se emplea la regionalización para obtener información hidrológica en sitios sin datos o con poca información (Sabahattin y Vijay, 2008).
En cada región homogénea se analiza que variables afectan en mayor medida al caudal, para integrarlas en ecuaciones que permitan calcular, con un margen de error aceptable, el caudal de descarga para diferentes recurrencias (Paris y Zucarelli, 2004).
En este trabajo de investigación, se analizó la cuenca del Arroyo Feliciano que posee una sección de control en su cauce principal: la estación “Paso Medina”, operada por la Subsecretaría de Recursos Hídricos de la Nación (SSRH).
El objetivo del trabajo fue obtener fórmulas de estimación de caudales, para cada una de las regiones definidas como hidrológicamente homogéneas, que permitan calcular el valor de caudal máximo, a partir de variables de fácil determinación, pertenecientes a cada subcuenca. Estas fórmulas pueden ser utilizadas como referencia para estimar valores de caudales máximos para distintas recurrencias en cuencas que presenten características similares a las regiones para las cuales fueron definidas Estos resultados no pretenden reemplazar a la modelación hidrológica en el cálculo de caudales, sino dar valores de referencia en cuencas no aforadas.
Desarrollo Descripción del área de estudio
La cuenca del arroyo Feliciano se encuentra ubicada en el noroeste de la provincia de Entre Ríos (Figura 1). Este arroyo es afluente del río Paraná. Pertenece a la Cuenca del Plata y su cuenca tiene un área de 8.203 Km2.
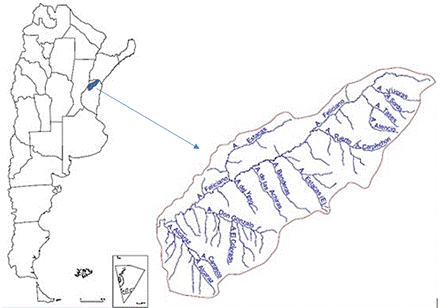
El arroyo Feliciano, curso principal de la cuenca, nace en la Cuchilla Grande, en el noreste de la provincia, fluye del oeste al sudoeste atravesando la provincia y se extiende por tres departamentos entrerrianos: Federal, Feliciano y La Paz. Sus afluentes más importantes son los arroyos Estacas, Don Gonzalo, Alcaraz, Puerto, de las Achiras y Banderas. La longitud del curso principal es de 265 Km siendo su elevación máxima de 80 m y la mínima de 20 m.
Análisis de frecuencia de caudales
Se utilizaron datos hidrométricos obtenidos a partir de la estación de aforo Paso Medina, operada por la SSRH, la cual registra valores de caudales desde el año 1975.
Se seleccionaron los valores máximos registrados en cada año hidrológico y se realizó un análisis de frecuencia aplicando el programa AFmulti, desarrollado por la Facultad de Ciencias Hídricas de la Universidad Nacional del Litoral (Cacik y Paoli, 1996). Este programa permite evaluar diferentes funciones de distribución y analizar gráficamente su ajuste.
En la Figura 2 se grafican las frecuencias experimentales y las distintas funciones de distribución analizadas. Mediante el cálculo de los errores cuadráticos medios de frecuencia (ECMF) y variable (ECMV) (Figura 3) y el análisis visual de la figura 2, se seleccionó la función de Pearson como la de mejor ajuste.


La función de distribución de Pearson se desarrolló en base a la función de distribución gamma y cuenta con tres parámetros: λ, β y ϵ que se obtienen en función de la desviación estándar, la media y el coeficiente de asimetría (Chow et al, 2000). La expresión de la función es la siguiente:
dónde:
X: variable aleatoria.
λ, β, ϵ: parámetros del método.
Г (β): función gamma (Abramowitz y Stegun, 1965).
Análisis de la distribución temporal adecuada para las precipitaciones de diseño
La precipitación de diseño o proyecto es una variable que se puede caracterizar a través de la intensidad, la duración y la recurrencia. Por ello se utilizaron las curvas Intensidad-Duración-Recurrencia (IDF) (Figura 4), desarrolladas en el proyecto de investigación “Estudio de Tormentas de diseño en cuencas extensas de la Provincia de Entre Ríos” (López et al., 2020), publicación del grupo de investigación en Hidrología de la Facultad Regional Paraná UTN. Se calcularon las intensidades a partir de las precipitaciones medias areales de la cuenca, para duraciones de 4, 6, 8, 10 y 12 días y para las recurrencias de 2, 5, 10, 20, 50 y 100 años.
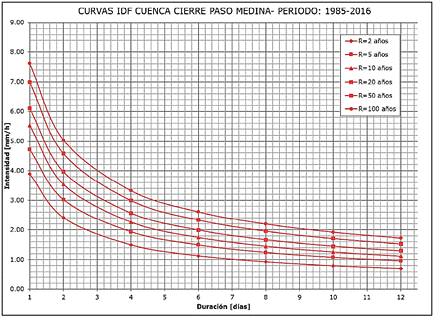
Figura 4: Curvas IDF - Cuenca del Arroyo Feliciano con cierre en Paso Medina (Fuente: “Estudio de Tormentas de diseño en cuencas extensas de la Provincia de Entre Ríos”. (López et al., 2020)
Las intensidades obtenidas de las IDF permiten el cálculo de la precipitación para la duración y recurrencia de interés. La distribución temporal de la precipitación se realizó a través de dos métodos: el método de patrones temporales y el de bloques alternos.
1. Patrones temporales
El método de patrones temporales se basa en utilizar porcentajes de precipitación para distintos intervalos de tiempo, los que se obtienen del análisis estadístico al que se llega observando la intensidad de las tormentas locales y dividiéndola en cuantiles. En este caso, se utilizó el patrón de la Figura 5, obtenido como un promedio de los resultados del estudio “Procedimientos para la Estimación de Tormentas de diseño para la provincia de Entre Ríos” (Zamanillo, 2018) de la UTN Concordia.

2. Bloques alternos
El método de bloques alternos consiste en ordenar los valores de precipitación, obtenidos de las curvas IDF para los distintos intervalos, ubicando el mayor valor en el centro de la duración de la tormenta y alternando los demás bloques en orden descendiente a un lado y al otro del máximo, como se indica en Figura 6.

Explotación del modelo hidrológico
Para simular el proceso de transformación de lluvia en caudal, se dispuso de un modelo calibrado con cierre en Paso Medina (Figura 7). El modelo hidrológico utilizado, implementado con el programa HEC HMS (Feldman, 2000), fue calibrado en el cierre con la información de caudales de la estación Paso Medina, en un estudio previo al presente trabajo (Puente de RP N° 5 sobre el Arroyo Feliciano, Justo Domé y Asociados S.R.L, 2019).

Justo Domé y Asoc. SRL. 2019
Figura 7 Modelo Hidrológico del Arroyo Feliciano con cierre en Paso Medina
Se realizó la explotación del modelo para las distintas duraciones de tormenta, las recurrencias y las dos distribuciones temporales, obteniendo valores de caudales.
Los caudales máximos obtenidos en la simulación se constataron con los determinados por análisis estadístico de caudales máximos observados en la Estación Paso Medina. Mediante la ecuación (2) Se calcularon el Error Cuadrático Medio (ECM) (Tabla 1) entre los resultados de caudales simulados y los determinados por análisis estadístico para cada distribución de probabilidades analizada en el punto “Análisis de Frecuencia de caudales”. En los caudales simulados, se consideraron los resultados obtenidos para precipitaciones distribuidas según el método de Bloques Alternos y por Patrones Temporales.
dónde:
n: cantidad de datos evaluados.
Qp: caudal estimado a partir de función de probabilidad.
Qo: Caudal observado.
Del análisis se concluyó, tanto gráfica (Figura 8) como analíticamente (Tabla 1), que la distribución temporal de tormentas de mejor ajuste era la de patrones temporales.
También se definió que las duraciones de tormentas, que generan los caudales de mayor precisión, eran las de 8 y 10 días (Figura 8).
Estas conclusiones se utilizaron posteriormente en el cálculo de hietogramas, para el resto de las subcuencas.


Categorización de subcuencas
Se realizó la clasificación de las subcuencas, categorizándolas en distintos órdenes, en función de la cantidad de tramos recorridos por el cauce principal dentro de una subcuenca hasta su cierre.
En la Figura 9 se grafica el modelo de categorización utilizado. Se asignó un orden de 1 a todas las subcuencas que no tienen tramos de tránsito, es decir, donde no se realiza el proceso de traslado de hidrogramas a través de cursos, en este caso los cursos principales se denominan cursos de primer orden. La clasificación del drenaje aumenta si los cursos confluyen. Al avanzar aguas abajo, cuando dos corrientes de orden diferente se encuentran, el canal aguas abajo aumenta su orden. De acuerdo con el orden de los tramos, se clasificaron las subcuencas en números de órdenes crecientes. Llegando así a tener un total de 15 órdenes de jerarquización.

La delimitación de cuencas y la determinación de los parámetros fisiográficos se realizaron a partir del análisis del modelo digital de elevación del terreno, con el programa QGIS (QGIS.org., 2022). Además, el mismo posibilitó visualizar la cuenca completa con sus cauces (Figura 10) y generar mapas para cada orden de subcuencas, como el de la Figura 11 donde se puede visualizar el orden 2 de la categorización.
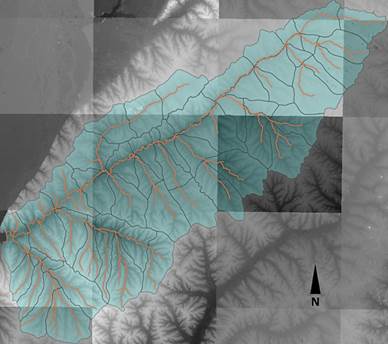

El modelo de cuenca se extendió hasta la desembocadura del Arroyo Feliciano en el río Paraná, obteniéndose con el programa QGIS los datos que permitieron extender el modelo hidrológico disponible hasta la desembocadura del arroyo. Para esto, se agregaron las subcuencas que se encuentran aguas abajo de la estación de aforos de Paso Medina.
Cálculo de hietogramas de subcuencas
La construcción de los hietogramas se realizó a partir de las curvas IDF disponibles (López et al., 2020), donde se definieron curvas IDF para subcuencas con cierres en secciones de control de interés (Figura 12).

Estudio de Tormentas de diseño en cuencas extensas de la Provincia de Entre Ríos”. López et al., 2020
Figura 12 Delimitación de Subcuencas para Curvas IDF
La selección adecuada de la curva IDF se realizó en función del promedio del área de las subcuencas pertenecientes a cada orden, adoptándose la correspondiente a la sección de control con área de aporte más cercana, afectada luego por la relación entre coeficientes de decaimiento areal del área media considerada y la correspondiente a la IDF, como se explica más adelante.
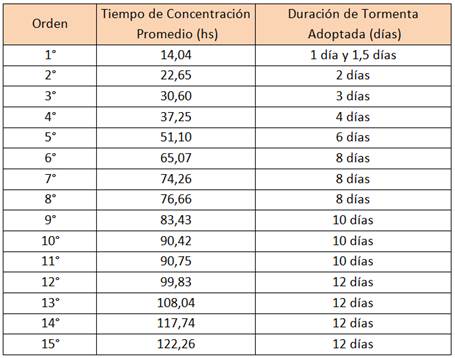
La determinación de la duración de las tormentas se realizó en función del tiempo de concentración (Tc) de las subcuencas. Para obtener este parámetro, se utilizó la fórmula empírica brindada por Kirpich, ecuación (3)
dónde:
Lcp: Longitud de cauce principal en km.
Dh: Diferencia de altura entre la cota superior e inferior
Según el análisis de errores mencionado anteriormente, la mayor aproximación de los caudales modelados con los observados en Paso Medina se presentó para tormentas de duraciones de 8 y 10 días, lo cual representa entre 2 y 3 veces el Tc en la estación de aforos, adoptándose esta relación para la determinación de la duración de tormenta en las distintas subcuencas (Tabla 2).
La distribución areal de las precipitaciones se consideró mediante la aplicación de un coeficiente de decaimiento areal obtenido a partir de ecuaciones definidas en “Estudio de Tormentas de diseño en cuencas extensas de la Provincia de Entre Ríos” (López et al., 2020), en función de las áreas de las subcuencas consideradas, la duración y la recurrencia de la tormenta.
Con la ecuación (4) se calcularon las precipitaciones medias areales (PMA) para cada una de las 15 agrupaciones de las subcuencas, para las 6 recurrencias definidas anteriormente.
PMA (X) = Precipitación Media Areal de la cuenca estudiada
PMA (ER) = Precipitación Media Areal de la Estación de Referencia
CDA (X) =Coeficiente de Decaimiento Areal de la cuenca estudiada, (se ingresa con el área de la cuenca).
CDA (ER) =Coeficiente de Decaimiento Areal Estación de la Estación de referencia, (se ingresa con el área de la estación de la referencia).
Las PMA resultantes se distribuyeron temporalmente, mediante el método de patrones temporales, obteniendo los hietogramas para cada subcuenca.
Estimación de caudales mediante modelación
A partir del modelo hidrológico inicial, se realizaron 15 modelos diferentes, uno para cada orden definido en la categorización y se realizó la explotación para los hietogramas de las distintas recurrencias, obteniendo así los valores de caudales máximos correspondiente a cada subcuenca y recurrencia.
Parámetros y variables seleccionados
La regionalización de caudales involucró la elección y cuantificación de aquellas variables consideradas relevantes para su estudio y la determinación de cuencas hidrológicamente homogéneas. Previamente, se seleccionaron 12 variables, para evaluar su incidencia en la respuesta hidrológica de las subcuencas, a saber:
Área
Raíz Cuadrada del Área
Perímetro
Índice de Compacidad
dónde:
P: perímetro de la subcuenca.
A: Área de la subcuenca.
Longitud del Cauce Principal
Pendiente del Cauce
dónde:
Lcp: longitud del cauce principal en m.
Dh: desnivel entre cota superior y cota inferior en m.
Tiempo de Concentración (3)
Coeficiente de Almacenamiento de Clark
dónde:
L: longitud del cauce principal.
S: pendiente del cauce medido en pie/milla.
Coeficiente Lambda
dónde:
R: Coeficiente de almacenamiento de Clark.
Tc: Tiempo de concentración.
Curva Número del Servicio de Conservación de Suelo de los Estados Unidos
Precipitación Media Areal (4)
Análisis Estadístico Multivariado
Los métodos estadísticos adquieren gran importancia en el manejo de datos hidrológicos debido fundamentalmente a su capacidad de optimización y síntesis en la generación de información. Además, al considerar numerosas variables, el problema en estudio presenta una múltiple referenciación y se conforman bases de datos de gran tamaño. Esta situación conlleva la necesidad de adoptar un enfoque multivariado para el procesamiento y el análisis de las variables ya que, de lo contrario, sólo se realizaría la interpretación circunscripta e independiente de cada una de ellas (Paris y Zucarelli, 2010).
Para poder realizar este análisis, con variables de distinto dimensionamiento, se optó por la normalización estadística. Esta consiste en la transformación de la escala de la distribución de una variable, con el objetivo de poder hacer comparaciones respecto de conjuntos de elementos, mediante la eliminación de los efectos de influencias. En otras palabras: todas las variables deben tener una media 0 y una desviación estándar de 1. Si antes de calcular los componentes no se estandarizan las mismas, aquellas cuya escala sea mayor dominarán al resto.
Se analizaron las variables mediante 3 métodos de análisis estadístico multivariado, utilizando el software RStudio (RStudio Team, 2015). Estos se describen a continuación:
Coeficientes de correlación
Tiene por finalidad visualizar si existe alguna relación entre dos o más variables, es decir, si los cambios en una o varias de ellas influyen en los valores de la variable dependiente. Si ocurre esto, indicará que las variables están correlacionadas o bien que hay correlación entre ellas.
El resultado del análisis se representa a través del Coeficiente de Correlación de Pearson, cuyo valor puede variar desde menos uno hasta uno. Cuanto más cercano a uno sea, en cualquier dirección, más fuerte será la asociación lineal entre las dos variables.
En la Figura 13 se muestra el resultado del análisis para la recurrencia de 2 años.

Análisis de Componentes Principales
Este método estadístico permite graficar los dos componentes principales de cada una de las variables, en un par de ejes de coordenadas en las direcciones X-Y. En este tipo de gráfico, pueden observarse las relaciones entre las variables según coincidan, o no, la magnitud y la dirección de los vectores.
En la Figura 14 se muestra el resultado del análisis para la recurrencia de 2 años.

Agrupamiento de Conglomerados - Clúster
El Análisis de Conglomerados es una técnica estadística multivariante que busca agrupar individuos o variables, a través de diferentes métodos o algoritmos, tratando de lograr la máxima homogeneidad en cada grupo y la mayor diferencia entre los grupos, arrojando un gráfico llamado dendrograma como resultado.
A partir de una matriz de individuos-variables, en este caso de 36 subcuencas con 12 variables en cada una, sitúa las variables o los individuos en grupos homogéneos, conglomerados o clústeres, no conocidos de antemano, pero sugeridos por la propia esencia de los datos, de manera que individuos que puedan ser considerados similares sean asignados a un mismo clúster, mientras que individuos diferentes se localicen en clústeres distintos.
En la Figura 15 se muestra el resultado del análisis para la recurrencia de 2 años.

Resultados del análisis multivariado. Selección de Variables
Del análisis anterior puede notarse que algunas variables están estrechamente relacionadas entre sí. Por ejemplo, el área y la raíz cuadrada del área, debido a que surgen a partir de un mismo dato alterado por una operación aritmética, por lo que en estos casos se decidió eliminar una de ellas, a fin de que las variables seleccionadas sean independientes.
Análogamente, sucede con el tiempo de concentración y el coeficiente de almacenamiento de Clark, los cuales dependen de la longitud de cauce y la pendiente. A su vez, el índice de compacidad se obtiene a partir del perímetro y del área.
Con el objetivo de corroborar la dependencia del tiempo de concentración y el coeficiente de almacenamiento con la longitud de cauce, se calcularon mediante el software RStudio los coeficientes de correlación entre estas variables en particular (Figura 16).

A partir de los coeficientes de correlación calculados, se pudo confirmar cuantitativamente que el coeficiente de almacenamiento posee una dependencia de la longitud de cauce y del tiempo de concentración. A su vez, el tiempo de concentración posee un 100% de dependencia de la longitud de cauce, por lo que el coeficiente de almacenamiento y el tiempo de concentración no fueron seleccionados como variables independientes para calcular caudales máximos.
Según los resultados extraídos, se destacaron como variables independientes con mayor correlación con el caudal: el área, la longitud de cauce y la pendiente. Además, se consideraron de importancia dos variables más que se relacionan directamente con el caudal, éstas son: precipitación media areal e índice o coeficiente de compacidad. La precipitación media areal depende de la duración y la recurrencia de la precipitación, afectada por un coeficiente de abatimiento que depende del área de la subcuenca. Adicionalmente, el índice o coeficiente de compacidad, a pesar de tener una correspondencia directa con el área, agrega la variable independiente del perímetro que caracteriza la forma de la cuenca.
Por lo mencionado anteriormente, las 5 variables elegidas fueron:
1. Área
2. Longitud de Cauce Principal
3. Precipitación Media Areal
4. Pendiente
5. Índice de compacidad
Regionalización en función de las características físicas
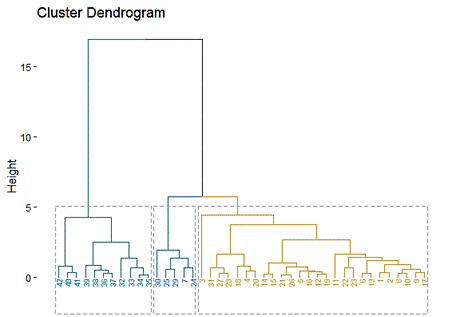
La agrupación de subcuencas, en regiones hidrológicamente homogéneas, se realizó mediante el software estadístico Rstudio, ejecutando un comando que utiliza un algoritmo de optimización llamado K-Means, lo que permitió determinar un número estimativo de regiones óptimas mediante la generación de dendogramas (Figura 17), en donde cada número representa una subcuenca.
Para corroborar este resultado se realizó un estudio por curvas de Andrews (Andrews, 1972) (Figura 18). Este consiste en una representación gráfica del comportamiento hidrológico de cada subcuenca, a través de funciones sinusoidales (Ecuación 9).
dónde:
X1, X2,... Xn: son las variables fisiográficas de la subcuenca.
t: representa en el rango entre - 2( y 2(
El resultado del análisis en conjunto del dendograma y curvas de Andrews (Figura 19 y 20) permitió definir 4 regiones hidrológicamente homogéneas.


Se realizó un análisis para determinar un procedimiento que permita identificar para cualquier subcuenca del Arroyo Feliciano a que región hidrológica corresponde. Para ello se determinaron las variables características en cada una de las regiones y se establecieron los valores límites, a partir de lo cual se construyó un diagrama de árbol de decisiones (Figura 21).

Ecuación de regionalización de caudales máximos
Para el cálculo de la ecuación regional de caudales máximos, se utilizó el método de regresión lineal múltiple, el cual permite generar un modelo lineal en el que el valor de la variable dependiente (Y) o respuesta se determina a partir de un conjunto de variables independientes llamadas predictores (X1, X2, X3…). Los modelos lineales múltiples siguen la ecuación 10:
Donde 𝛽0 es la ordenada al origen, el valor de la variable dependiente cuando todos los predictores son cero. 𝛽1 es el efecto promedio que tiene el incremento en una unidad de la variable predictora Xi, manteniéndose constantes el resto de las variables, los mismos se conocen como coeficientes parciales de regresión. Y 𝑒i es el residuo o error, la diferencia entre el valor observado y el estimado por el modelo de regresión.
Para la conformación de la ecuación regional de caudales, se seleccionaron las 3 variables de mayor correlación con el caudal que son: el Área (A), la Pendiente (P) y la Precipitación Media Areal (PMA). Considerando que el caudal no guarda una relación lineal con las variables definidas, las ecuaciones se expresaron en función del logaritmo natural. Adoptando la forma de la ecuación 11:
El caudal máximo se determina con el antilogaritmo de la ecuación 11 como se indica en ecuación 12.
La ecuación se definió para una recurrencia de 2 años. Para las otras recurrencias se determinó el índice de creciente (IC) que relaciona el caudal de 2 años con los caudales para otras recurrencias. El IC se calculó a partir de los caudales modelados para las distintas subcuencas de cada región homogénea. De esta forma, multiplicando el resultado obtenido de la ecuación de regionalización para 2 años (Q2años) por el IC (ecuación 13) de la recurrencia de interés, se determina el caudal para esta recurrencia.
Resultados
A continuación, se presentan los resultados para cada región:
Región 1
Ecuación regional de caudal:
Índice de creciente:
Región 2
Ecuación regional de caudal:
Índice de creciente:
Región 3
Ecuación regional de caudal:
Índice de creciente
Región 4
Ecuación regional de caudal:
Índice de creciente
donde:
Q2años: caudal para una recurrencia de 2 años en m3/s.
A: área de la cuenca en km2.
P: pendiente media del cauce en m/m.
PMA: precipitación media areal en la cuenca para 2 años de recurrencia y una duración de tormenta de dosa tresveces el tiempo de concentración de las subcuencas en . Se considera una duración de entre 8 y 12 días para la Región 1, de entre 1.5 y 4 días para las Región 2 y Región 3 y, entre 1 y dos días para la Región 4. Los valores adoptados para cada región se encuentran en “Tabla 2 - Tiempos de Concentración Promedio y Duraciones de Tormenta Adoptadas”.
Ic: índice de creciente.
Tr: recurrencia en años.
Conclusiones
A través de este estudio, se ha logrado elaborar un procedimiento para la estimación de caudales máximos en las subcuencas del Arroyo Feliciano, a partir de fórmulas simples y de variables de fácil obtención, como son el área, la precipitación máxima media areal y la pendiente del cauce principal.
Los errores, entre los caudales estimados con las ecuaciones de regionalización y lo modelados, resultaron inferiores al 20%. Esto constituye un aporte significativo en el estudio de caudales máximos, dentro de las cuencas extensas de la provincia de Entre Ríos, ya que se logra reducir la incertidumbre en el diseño de obras hidráulicas, al poder contrastar estos resultados con los resultados de la modelación hidrológica de cuencas no aforadas de características similares.
Además, se elaboró un árbol de decisiones, el cual facilita el uso de las ecuaciones

