











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
INTRODUCCION
El análisis de datos georreferenciados provee la oportunidad de modelar la variabilidad espacialmente estructurada tanto a escala de lote como a escala regional. La Interpolación espacial conocida como kriging está basada en el ajuste de funciones de variogramas y es usada para predecir valores de una variable analizada en sitios no muestreados de un dominio espacial. Los valores predichos sobre una malla de predicción, pueden luego ser usados para generar mapas temáticos que son prácticamente continuos en el espacio (Betzek et al., 2019). Numerosos modelos teóricos de variogramas (Cressie y Wikle, 2011) pueden ser ajustados desde los datos muestreados para realizar interpolaciones espaciales. La selección de un modelo en particular se puede realizar a partir de medidas que evalúan el desempeño de las predicciones espaciales (Córdoba, Paccioretti, Giannini Kurina, Bruno y Balzarini, 2019). Ajustar y evaluar cada uno de los distintos modelos de variograma puede ser complejo. La automatización del proceso para la selección del modelo espacial y la predicción necesaria para el mapeo ayuda a la implementación de métodos eficientes para el análisis de datos espaciales.
El mapeo univariado y multivariado de datos georreferenciados es útil para delimitar zonas homogéneas, tanto a escala fina (Córdoba, Bruno, Costa, Peralta y Balzarini, 2016) como a escala regional (Giannini Kurina, Hang, Córdoba, Negro y Balzarini, 2018). Al explorar la variabilidad especial dentro de un lote cultivado, por ejemplo, los agricultores pueden identificar los factores principales que impactan en el rendimiento. Por lo tanto, un objetivo común en la agricultura basada en datos (agricultura de precisión) es la clasificación no supervisada de sitios dentro del lote para identificar áreas similares dentro del lote con respecto a los factores limitantes para el desarrollo del cultivo (Moral, Terrón y Marques da Silva, 2010). Estas áreas homogéneas (zonas de manejo) constituyen la base de la gestión agrícola sitio-específica.
Los datos provenientes de monitores de rendimiento son frecuentemente usados para analizar la variabilidad intralote y realizar zonificaciones. Sin embargo, otras capas de datos (mediciones sobre distintos sitios del lote) pueden estar disponibles; por ejemplo, mediciones de electroconductividad aparente, profundidad de suelo y propiedades edáficas. En estos contextos, de múltiples capas de datos, la zonificación multivariada es recomendable (Taylor, McBratney y Whelan, 2007). Para este fin, existe especial interés en métodos de clúster que consideren la correlación espacial presente entre las observaciones de una misma variable tomada en distintos sitios del terreno (autocorrelación espacial) y la correlación entre variables (Córdoba, Bruno, Costa y Balzarini, 2013). Sin embargo, los métodos de conglomeración o clustering de sitios que contemplan la espacialidad de los datos, no se encuentran disponibles en la mayoría de los softwares usados para la delimitación de zonas homogéneas en sentido multivariado.
Otros problemas asociados al análisis de datos espaciales tienen que ver con el manejo de las bases de datos previo al análisis. Usualmente provienen de sistemas de información geográfica (SIG) o se encuentran ligados a sistemas de posición geográfica (GPS) que almacenan datos en formatos diversos. En casos donde los datos se colectan automáticamente (como con tecnologías de agricultura de precisión), las bases de datos pueden contener numerosos errores (Sudduth y Drummond, 2007). En este trabajo se describe una nueva aplicación de software llamada FastMapping, la cual ha sido desarrollada para automatizar, en una interfase simple y fácil de usar, un protocolo completo de análisis estadísticos para datos espaciales que incluye la automatización del preprocesado de la base de datos, la interpolación geoestadística para la construcción y visualización de mapas de variabilidad espacial y la clasificación de sitios en zonas homogéneas a partir de un algoritmo multivariado con restricción espacial. Los objetivos de este trabajo fueron analizar la variabilidad intralote del rendimiento de trigo y covariables de sitio, y comparar la zonificación multivariada producida por FastMapping con la obtenida a partir de software comercial de amplia difusión en agricultura de precisión.
MATERIALES Y MÉTODOS
Software
El software FastMapping fue desarrollado utilizando paquetes especializados del lenguaje de programación R (R Core Team, 2019), los cuales posibilitan la aplicación de protocolos de depuración, interpolación y clasificación uni y multivariada en el contexto de datos correlacionados espacialmente (Córdoba et al., 2013; Vega, Córdoba, Castro-Franco y Balzarini, 2019). La interfaz gráfica de usuario está generada principalmente con funciones del paquete shiny (Chang, Cheng, Allaire, Xie y McPherson, 2019). La depuración espacial se realiza con funciones del paquete spdep (Bivand y Wong, 2018). El ajuste de semivariogramas y la interpolación espacial usa los paquetes automap (Hiemstra, Pebesma, Twenhofel y Heuvelink, 2009), fields (Nychka, Furrer, Paige y Sain, 2017), geoR (Ribeiro y Diggle, 2018) y raster (Hijmans, 2019). La clasificación es realizada con los paquetes adespatial (Dray, Sáíd y Débias, 2008) y e1071 (Meyer, Dimitriadou, Hornik, Weingessel y Leisch, 2019). FastMapping está alojado en un servidor de la Universidad Nacional de Córdoba (UNC). El código de programación se encuentra en https://github.com/PPaccioretti/ FastMapping. Para comenzar una sesión de FastMapping, es necesario contar con conexión a Internet y se debe ingresar a https://fastmapping. psi.unc.edu.ar.
Datos de ilustraciónSe utilizó para procesar con FastMapping, una base de datos de un lote comercial (60 ha) de trigo (Triticum aestivum L.) bajo agricultura continua, localizado en el sureste de la provincia de Buenos Aires. Los datos incluían medidas georreferenciadas de rendimiento de trigo en una campaña. Además, se midió valores de electroconductividad aparente (ECa) en dos profundidades, 0-30cm y 0-90cm, elevación y profundidad de suelo. Los valores de rendimiento fueron obtenidos con monitores de rendimiento. Las medidas de ECa fueron tomadas usando una sonda Veris 3100 (VERIS technologies, Salina, KS, USA). La medición de la elevación del terreno se realizó utilizando un DGPS Trimble R3(Trimble Navegation Limited, Sunnyvale, CA, USA). La profundidad del suelo fue medida usando un penetrómetro hidráulico.
Análisis estadísticoPreprocesamiento de datos
Previo al procesamiento, se usó FastMapping para transformar el sistema de coordenadas geográficas a cartesianas Universal Transversal de Mercator (UTM). Todas las variables fueron depuradas y re-escaladas a una grilla regular de 30x30m utilizando FastMapping. En la depuración de datos, se removieron datos relacionados a los efectos bordes. Además, se eliminaron valores que se encontraban por fuera del patrón general de los datos. Para esto, el conjunto de datos se limita dentro de un rango de variación razonable, donde los valores mínimos y máximos se obtienen a partir del conocimiento previo de la distribución. Luego, se calcula la media y la desviación estándar (DE), eliminando valores que se encuentren por fuera del intervalo media ±3 DE, dado que teóricamente aproximadamente el 90 % de los datos de una variable aleatoria se encuentra dentro de este rango (outlier global). Por último, se eliminaron aquellos valores que, si bien su observación es posible para la distribución de la variable, difieren significativamente de su vecindario (outlier espacial). Para detectar estos valores, se utiliza el índice de autocorrelación espacial local de Moran (IM) (Anselin, 1995) y el gráfico de dispersión de Moran (Anselin, 1996). Si al menos uno de estos criterios detecta la observación como rara, ésta es eliminada automáticamente. Para calcular la autocorrelación espacial con el índice de Moran, es necesario generar una red de vecindarios, en este se consideraron sitios vecinos a aquellos que se encontraban dentro de una distancia de 35 metros.
Mapeo de la variabilidad espacial Mapeo univariado
Para el mapeo de la variabilidad espacial, FastMapping ajusta 11 modelos teóricos de semivariogramas: Exponential, Shperical, Gaussian, Matern, Matern Stein’s, Circular, Linear, PowerWave, Pentaspherical y Hole (Hiemstra et al., 2009). Para la selección del modelo de mejor ajuste utiliza un proceso de validación cruzada (Kohavi, 1995) que evalúa la capacidad predictiva del modelo de correlación espacial seleccionado. Aquel con el que se obtiene menor error cuadrático medio de predicción es automáticamente seleccionado para ser usado en la interpolación espacial.
FastMapping utiliza distintos métodos de kriging (Webster y Oliver, 2007) para realizar interpolaciones espaciales y poder predecir los valores de la variable en sitios no muestreados. Este método proporciona el mejor predictor lineal para el valor de la variable en un sitio, suministrando además un error de predicción conocido como varianza kriging, que depende del modelo de variograma ajustado y de las localizaciones de los datos originales. La varianza kriging brinda la posibilidad de analizar la calidad de las predicciones obtenidas por interpolación. Para evitar el uso de información proveniente de muestras redundantes, el método kriging pondera de forma distinta muestras que están cerca entre sí respecto a muestras que están más distantes. Los parámetros del variograma ajustado determinan las ponderaciones de los datos que serán usados en la interpolación.
Mapeo de variabilidad multivariada
Sobre la base de datos depurada y re-escalada se pueden aplicar diferentes versiones del análisis de clúster no jerárquico fuzzyk-means (Bezdek, Coray, Gunderson y Watson, 1981). FastMapping permite implementar fuzzy k-means sobre las mediciones originalmente medidas, las obtenidas por interpolación durante el re-escalado o sobre las componentes principales espaciales del archivo en análisis (Córdoba et al., 2013). Para realizar el Análisis de Componentes Principales espacial (Dray, Saíd y Débias, 2008), se requiere primero calcular la matriz de ponderación espacial en forma similar a la realizada para el cálculo del índice de Moran. Para determinar el número óptimo de clústeres, se calculan los coeficientes de partición (FPI, del inglés fuzziness performance index) y de entropía de la clasificación (NCE, del inglés normalized classification entropy) (Bezdek et al., 1981) junto con el índice Xie-Beni (Xie y Beni, 1991). Además, FastMapping combina estos índices, produciendo un índice resumen, para obtener una única métrica para determinar el número de clúster óptimo (Galarza, Mastaglia, Albornoz y Martínez, 2013). Para aplicar el algoritmo fuzzy k-means, es necesario definir el parámetro conocido como exponente difuso. En el contexto de generación de zonas de manejo en agricultura de precisión, usualmente se utiliza un valor de 1,3 (Odeh, McBratney y Chittleborough, 1992). El algoritmo de clúster necesita la especificación de una métrica de distancia para evaluar la similitud/ diferencia entre los objetos a agrupar. La métrica de distancia, Euclídea, Diagonal y de Mahalanobis son frecuentemente usadas en delimitación de zonas de manejo (Fridgen, Kitchen y Sudduth, 2004). FastMapping provee de manera automática la comparación de medias entre zonas para cada una de las variables involucradas en el análisis multivariado. La comparación de medias se realiza con varianzas calculadas después del ajuste por correlación espacial según la siguiente expresión
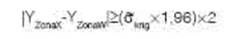
donde es la media de la Zona X, es la media de la Zona W y a es la mediana de la desviación estándar kriging; el valor 1,96 es el cuantil 0,975 de la distribución normal estándar que se supone siguen las diferencias de medias y el valor 2 deriva de la condición bilateral de la hipótesis sobre igualdad de medias de la variable de interés entre zonas (Taylor et al., 2007).
Implementación del mapeo de variabilidad espacial en FastMapping
Al cargar el archivo de datos crudos (Wheat raw data, disponible en FastMapping) FastMapping transforma el sistema de coordenadas geográficas a un sistema de coordenadas cartesianas UTM, luego de especificar el hemisferio (sur) y el área (20). El usuario puede cargar una base de datos donde se especifican los vértices sobre el cual se realizará la interpolación. Cuando se selecciona una columna como Target variable las pestañas Depuration, Prediction, Results, Cluster y Report se habilitan. En la pestaña Depuration las opciones Global Outliers, Spatial Outliers y Remove borders pueden dejarse con sus valores por defecto y de esta manera, previo a realizar la interpolación, el software elimina los valores menores o iguales a cero, observaciones que se encuentran dentro de los 20 metros del borde y valores que se encuentran por fuera del intervalo de la media ±3 DE. Para eliminar outlier espaciales, se consideran vecinos aquellos sitios que se encuentran hasta una distancia determinada (20 metros). En la pestaña Prediction, la opción correspondiente a los modelos teóricos a ajustar y si se selecciona Automatic, FastMapping ajustará uno a uno, 11 modelos teóricos de variograma. Para la interpolación espacial, si se selecciona la opción Ordinary se realizará una predicción kriging puntual. Para esto se definen la cantidad de vecinos de cada punto a predecir (de 7 a 25). Por defecto, la interpolación se realiza sobre una grilla de 30x30m (opción Grid dimentions). Estos procedimientos se repiten para cada variable de la base de datos para conformar el archivo que se debe ingresar para realizar la zonificación multivariada. El archivo denominado Zoning a field from yield and soil properties, disponible en FastMapping constituye un ejemplo del formato de datos necesario implementar una zonificación multivariada.
Evaluación de Fast Mapping
El software MZA (del inglés Management Zone Analyst) ha sido desarrollado para utilizar la información del lote y delimitar clases o potenciales zonas de manejo y se encuentra ampliamente difundido como software comercial para la zonificación de lotes en agricultura de precisión (Fridgen et al., 2004). En este trabajo, se comparó el desempeño de FastMapping y MZA a través del análisis de la base de datos de referencia, con ambos softwares. Para el análisis de clúster en MZA se utilizó como medida de similitud la distancia Mahalanobis, la cual se recomienda cuando se utilizan variables correlacionadas y con varianzas heterogéneas como input del análisis (Fridgen et al., 2004). Otras opciones de configuración utilizadas fueron: número máximo de iteraciones=300 y criterio de convergencia=0,0001. El exponente difuso se fijó en el valor convencional de 1,30 (Odeh et al., 1992).
La zonificación se realizó con los datos previamente depurados y reescalados en FastMapping ya que MZA no contiene facilidades para el preprocesamiento de datos. Las visualizaciones de los resultados producidos por FastMapping se comparan con visualizaciones realizadas con gráficos generados en R para representar los clústeres de sitios producidos por MZA ya que los resultados de la zonificación de MZA se entregan en formato de un archivo de texto.
RESULTADOS Y DISCUSIÓN
Mapeo univariado
Previo a la depuración, los valores de rendimiento en grano de trigo se encontraban entre 0,001 t ha-1 y 24 t ha-1, con media de 4,62 t ha-1 y DE 2,07 t ha-1. Luego de la depuración de la base de datos, el valor mínimo de rendimiento fue de 2,04 t ha-1 y el máximo de 7,34 t ha-1 con media de 4,82 t ha-1 y DE 1,52 t ha-1. Aun cuando la presencia de valores extremos de rendimiento no impactó significativamente en la estimación de la media, la depuración de estos valores puede cambiar la varianza de la variable en estudio y sesgar la estimación de los modelos de variabilidad espacial que serán usados para el mapeo, por ello es recomendable la eliminación de valores raros previo a la aplicación de métodos de estadística espacial. Luego de procesar numerosos mapas de rendimiento, se observa que el proceso de depuración mejora las predicciones espaciales y reduce los efectos negativos de los errores de lectura en la distribución espacial del rendimiento (Vega et al., 2019). En la base de datos de trigo, sin depuración, el error de predicción fue del 20.2 % respecto a la media del rendimiento de trigo; luego de la depuración ese error disminuyó a 7,7 %. Del total de observaciones (n = 9810), el 14.2 % fueron eliminadas por encontrarse a una distancia menor a 20 metros de los bordes. En agricultura de precisión las observaciones muy cercanas a los límites del lote suelen contener errores asociados a los manejos de cabecera y giros de las maquinarias, razón por la cual se recomienda su eliminación (Sudduth y Drummond, 2007). El 1,82 % de los datos fueron considerados outliers globales y el 14,8 % se identificaron como outilers espaciales. Luego de interpretar estas observaciones raras con el gráfico de dispersión de Moran, FastMapping eliminó automáticamente el 4,7 % de los datos. En la pestaña Plot Condition Data de FastMapping, pueden visualizarse el conjunto de las observaciones que se usarán en la interpolación y la posición de aquellas eliminadas por distintos motivos. En total, para el lote de trigo bajo análisis, se eliminó el 35,5 % de los sitios debido a la presencia de valores raros (Figura 1).
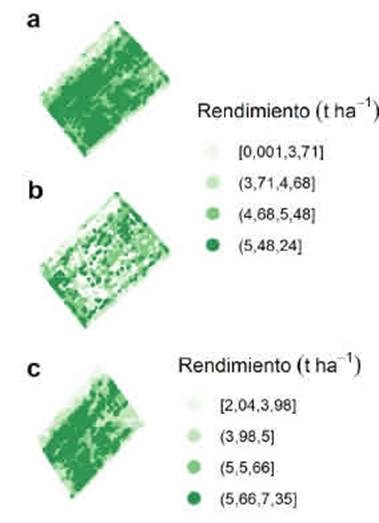
Figura 1 Gráficos mostrando sitios y su valor; a) datos crudos; b) datos eliminados por distintos motivos durante la depuración, c) observaciones no eliminadas.
Para el ajuste del semivariograma experimental, el modelo teórico que menor error de predicción generó fue el propuesto por Matern con la parametrización de Stein (Stein, 1999). Las estimaciones de los parámetros del semivariograma fueron Nugget = 0, Sill Parcial = 1,1, Rango = 68,4 y kappa = 0,4. Estos resultados sugieren que los datos están correlacionados hasta una distancia de 68,4 m y que la variabilidad observada se encuentra espacialmente estructurada. Los valores predichos y la varianza kriging pueden descargarse desde la pestaña Predicted. Los datos extraídos durante la depuración y su condición de extracción también pueden ser descargados.
Mapeo multivariado
Cuando se selecciona más de una variable para el análisis, FastMapping habilita la pestaña Multivariate posibilitando la clasificación multivariada mediante el método KM-sPC (Córdoba et al., 2013). Por defecto, el software realiza la estandarización de las variables y almacena las componentes espaciales que explican hasta el 70 % de la variabilidad total. Para el lote de trigo, analizado no solo con el rendimiento sino también con las covariables de sitio descriptas en la sección Datos, el índice resumen sugirió dos conglomerados de sitios o zonas. Para la interpretación de la zonificación obtenida, se mapeó la variabilidad espacial de cada una de las covariables de sitio y del rendimiento en grano. Los resultados de la zonificación también se presentan como un mapa de sitios geoposicionados donde estos son coloreados de acuerdo con el clúster al que fueron asignados.
La variabilidad espacial de la electroconductividad aparente, en ambas profundidades (Figura 2 a y 2 b) y la variabilidad de la profundidad efectiva del suelo (Figura 2 d), ponen de manifiesto la existencia de un área con menores valores de electroconductividad aparente y mayor profundidad de suelo. Esta depresión ha sido determinante en la conformación de las zonas homogéneas (Figura 2 f), donde se observan las dos zonas delimitadas por el algoritmo de clúster KM-sPC. La variabilidad espacial de rendimiento de trigo para la campaña analizada mostró, por el contrario, menos estructuración espacial. FastMapping reportó diferencias estadísticamente significativas entre medias de zonas para todas las variables medidas a excepción del rendimiento en grano (a = 0,05).
Comparación de FastMapping con MZALos procedimientos realizados con MZA requirieron más tiempo computacional que con FastMapping. Para visualizar los clústeres generados con MZA, los resultados en formato de texto debieron exportarse a otro software, mientras que en FastMapping pueden visualizarse dentro del mismo ambiente de trabajo. El software MZA reemplaza las celdas vacías por ceros, sin advertir este cambio al usuario, mientras que FastMapping, realiza el análisis sin considerar las celdas vacías. El remplazo por el valor cero, principalmente en situaciones con muchos datos faltantes, puede ocasionar problemas en las estimaciones de variabilidad espacial. FastMapping permite importar datos de diversos formatos mientras que MZA se restringe a datos de texto con las columnas delimitadas por coma. El análisis de los datos con FastMapping pudo realizarse sin necesidad de cambiar el ambiente de trabajo dado que la depuración, la interpolación espacial y la clasificación multivariada están integrados en el software. La velocidad de cómputo de FastMapping dependerá de la memoria disponible en el servidor, pero usualmente lleva algunos minutos correr un análisis completo para obtener el mapa deseado.
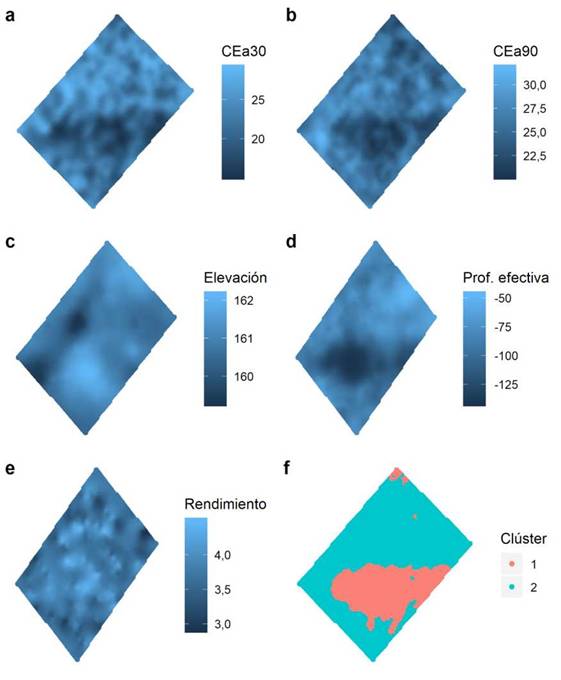
Figura 2 Mapeo de la variabilidad del lote en estudio para cinco variables medidas: a) conductividad eléctrica aparente 0-30 cm; b) conductividad eléctrica aparente 0-90 cm; c) elevación; d) profundidad efectiva del suelo; e) rendimiento de trigo; f) mapeo de la variabilidad multivariada contemplando todas las características anteriores.
La zonificación producida por FastMapping fue menos fragmentada (Figura 3) y las diferencias de medias para variables de suelo entre las dos zonas delimitadas, constituyen un resultado de referencia que permite comparar los dos softwares. Las zonas definidas por FastMapping mostraron mayor diferencia de medias para todas las variables respecto a las zonas producidas con MZA (Tabla 1). Al menos, en este campo se observó una mejora de la zonificación. El algoritmo KM-sPC que implementa FastMapping para la zonificación, ha mostrado que puede producir zonas más contiguas cuando la correlación espacial entre las variables es alta (Córdoba et al., 2013). Sin embargo, en varias aplicaciones de fuzzy k-means, que es el algoritmo implementado en MZA, se observó el inconveniente de una alta fragmentación de las zonas (Frogbrook y Oliver, 2007; Ping y Dobermann, 2003).
CONCLUSIÓN
La innovación metodológica de FastMapping es la integración de una etapa de pre-procesamiento de datos orientada a eliminar anomalías en datos espaciales, la construcción y validación de mapas de variabilidad espacial y la delimitación y validación de zonas homogéneas, tanto a escala de lote como a escala regional. Aplicado en datos de agricultura de precisión FastMapping mejoró la zonificación lograda respecto a métodos convencionales de clasificación, delimitando zonas con mayores diferencias en variables de suelo y topografía. La disponibilidad de aplicaciones basadas en R, con una interfaz amigable, permite mejorar las bases metodológicas y computacionales del análisis de datos espaciales.
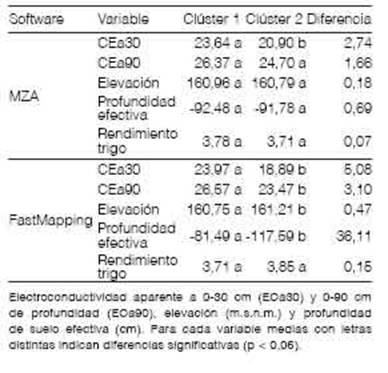
Tabla 1 Comparación y diferencia de medias de variables medidas entre zonas delimitadas por Management Zone Analyst (MZA) y FastMapping.
AGRADECIMIENTOS
Las investigaciones metodológicas que sustentan el protocolo de análisis implementado en FastMapping y su desarrollo son subsidiadas por el proyecto PID 2018 del MinCyT de la Provincia de Córdobay por el proyecto PROIINDIT 2019 de la SeCyT de la Facultad de Ciencias Agropecuarias,UNC, Córdoba, Argentina.

